网络结构
Block
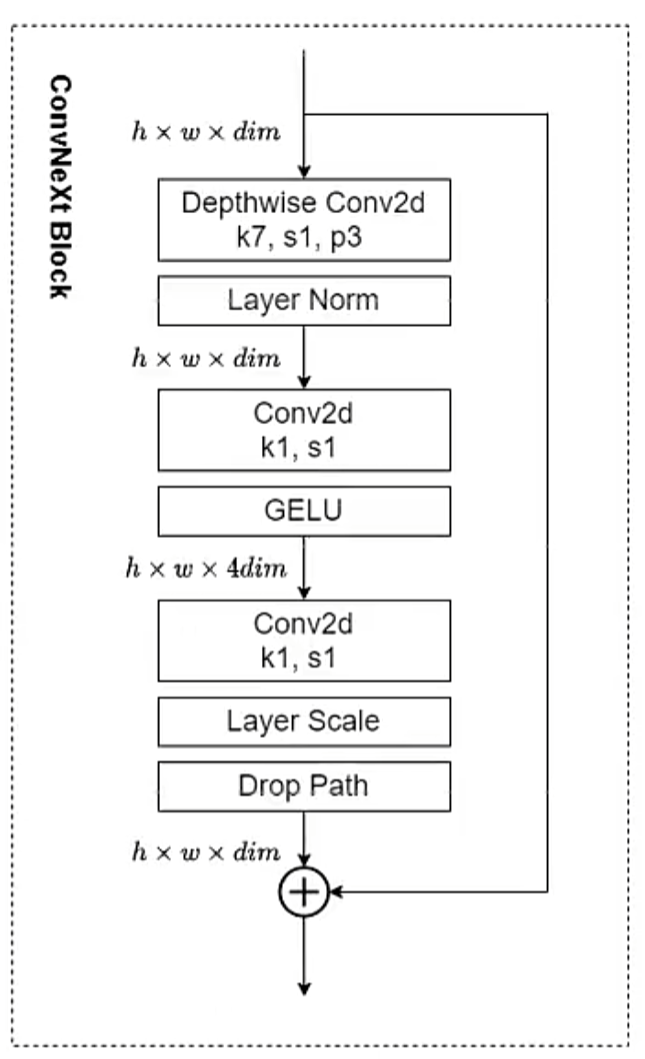
1 | class Block(nn.Module): |
整体结构
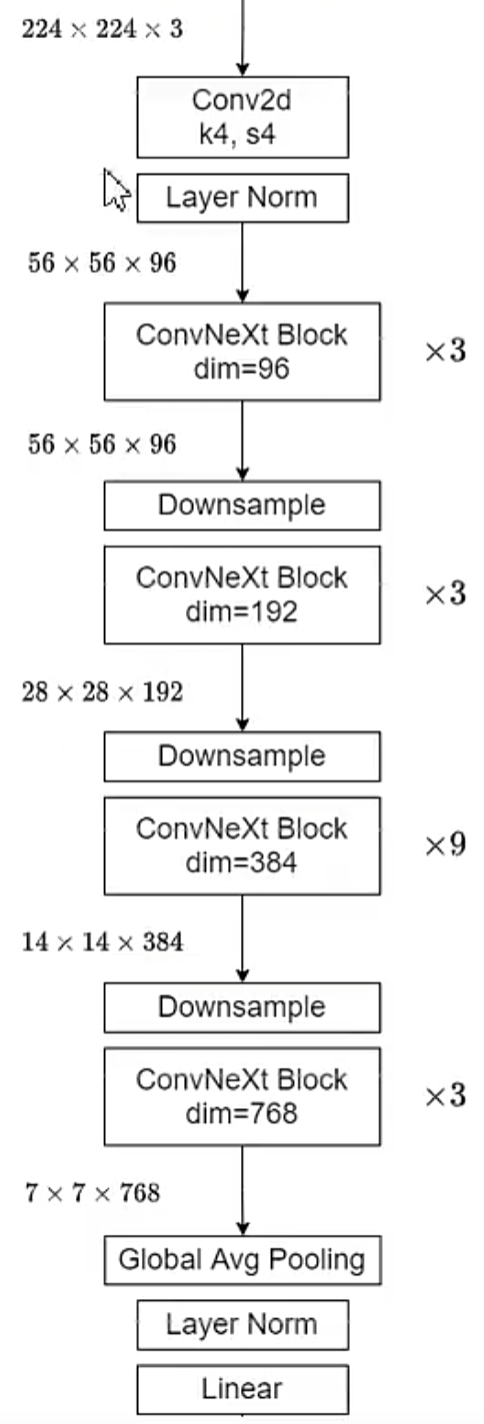

1 | class ConvNeXt(nn.Module): |
v5对应的配置参数
1 | # YOLOv5 backbone |
1 | class Block(nn.Module): |
1 | class ConvNeXt(nn.Module): |
1 | # YOLOv5 backbone |
Author: CY
Permalink: http://example.com/2022/03/30/convnext/
License: Copyright (c) 2019 CC-BY-NC-4.0 LICENSE
Slogan: Do you believe in DESTINY?