1. Module类
Behind the scenes, PyTorch overrides the
__setattr__function innn.Moduleso that the submodules you define are properly registered as parameters of the model.
1 | class MyModule: |
Registering modules
1 | layers = [nn.Linear(m,nh), nn.ReLU(), nn.Linear(nh,10)] |
- module中的__getattr中有三个魔法函数,其有三个成员变量分别是
_parameters、_buffers(统计量)和_modules
1 | # 实例化模型后,参数已初始化 |
1 | # 补充:model.modules(), model.children(), model.named_children(), model.parameters(),model.state_dict() |
- module中的
state_dict方法- 首先,通过
_save_to_state_dict方法先将当前模块的parameters和buffers变量存入destination字典 - 然后,遍历
self.modules.items()子模块,将每个子模块的parameters和buffers变量存入destination字典 - 最后返回
destination字典中包含所有模型状态参数,OrderedDict[key, value]
- 首先,通过
1 | module.state_dict().keys() |
-
module中的
parameter方法- 注意
parameter与_parameters区分,前者返回的是迭代器,包括当前模块和各个子模块的参数。后者返回的是当前模块中的参数。 - 其中会执行
named_papameters最终返回的是个迭代器对象[key, value]
1
2for p in test_module.named_parameters():
print(p) - 注意
-
module中的
train方法dropout和batchnorm都继承了Module类,都属于模型的子模块,当把模型设置为训练模式和验证模式时,相应的子模块也会设为对应的训练或验证模式
2. 自动微分Forward与Reverse模式

特点: 前向计算过程中当前节点相对某个输入结点的梯度可计算得到;每次只能得到一个输入节点的导数如图中的x1

特点: 反向计算过程中需要等待前向计算结束;一次性可以算出所有节点导数
图片出处:Automatic Differentiation in Machine Learning: a Survey
3. 算子融合
1 |
|
4. Hooks机制
Pytorch提供的hooks机制能让用户可以往计算流中的某些部分注入代码,一般来说这些部分无法直接从外部访问。其中主要有两种hooks,一种是添加到张量上的hooks,另一种是添加到Module上的hooks。
4.1 添加到张量上的hooks
这些添加的hooks能够让用户在反向传播的过程中访问到计算图中的梯度。
下面先来看看反向传播的一个具体例子。
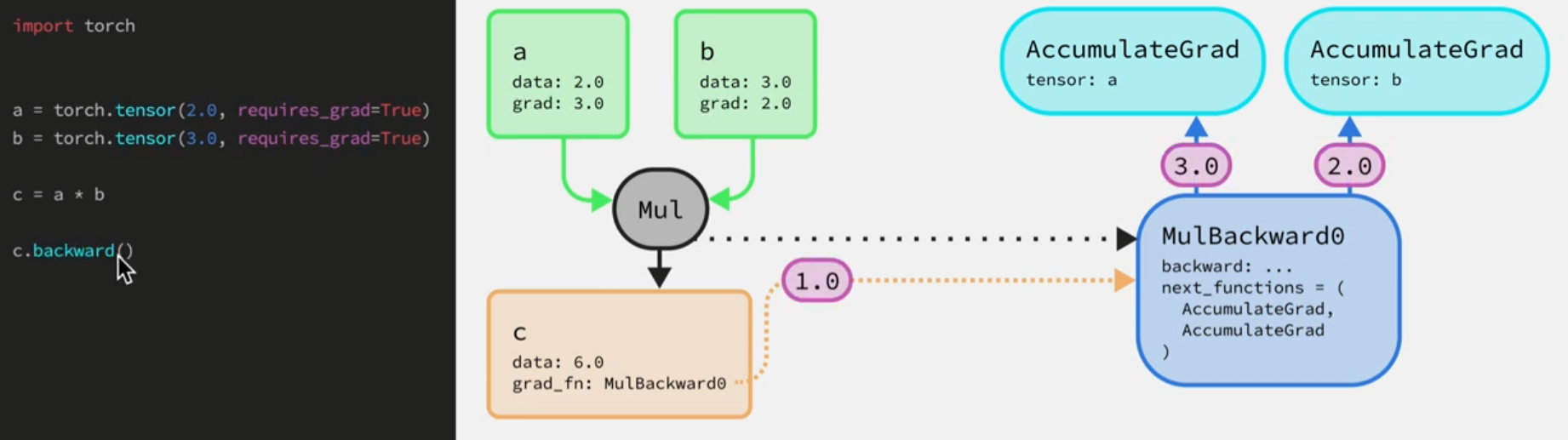
-
当我们将张量
a和b相乘的同时也在构建后向图,即创建了一个名字是MulBackward0的节点(其中next_functions表示梯度接下来要传递的到哪些节点即操作的输入),还有两个AccumulateGrad节点(将反向传播过程中对应张量的梯度作累加)。最后得到的梯度值将保存到叶子张量上(绿框)。 -
张量c属于中间节点,其中grad_fn属性指向后向图中的MulBackward0节点,c.backward()就是对应这个过程将起始梯度传给MulBackward0节点。然后再将该梯度传给MulBackward0节点中的backward函数(本质就是将输入梯度乘对应值得到输入张量的梯度)。本例中前传a*3和2*b所以此节点对应张量a和b的梯度为3,2。最后要将输出梯度1分别乘3,2得到输入梯度,然后传递给
a和b的AccumulateGrad节点来累加梯度,该节点将最终的梯度赋值给对应张量的grad属性。
以上整个过程一旦调用了.backward()反向传播过程中中间节点所产生的梯度(红框)都是无法访问到的,无法打印、修改,用户只能查看反向回传完之后叶子节点上的梯度。
hooks的作用在于能够让用户访问到反向传播过程中的梯度张量,同时可以修改这些梯度值。
我们给中间的张量都添加hooks看看计算图会有什么变化
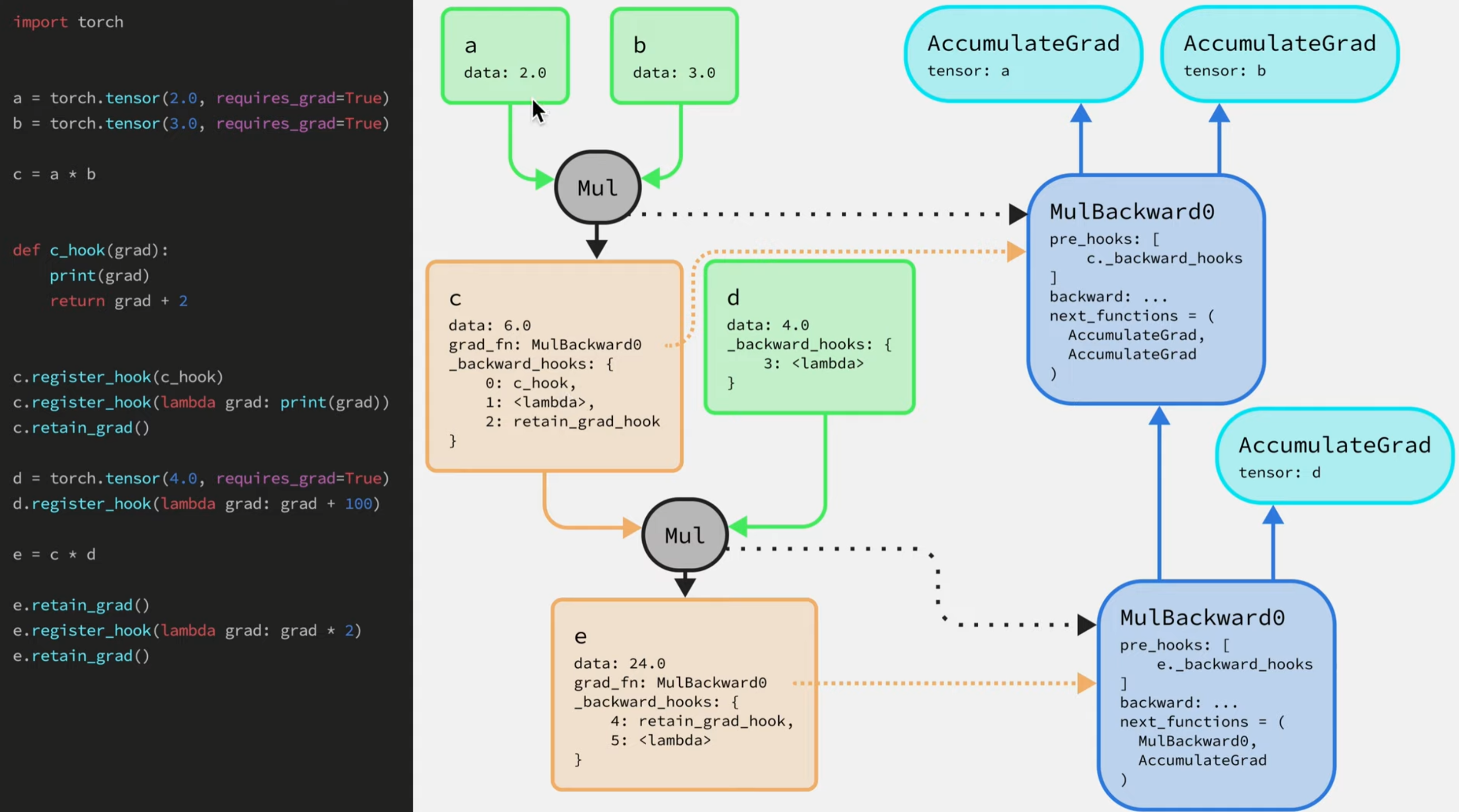
-
第一个添加的
hook:c.register_hook中传入了一个函数c_hook,该函数有一个参数表示梯度,并可以返回一个新梯度。当向张量c注册这个hook函数,首先它会被添加到张量c的_backward_hooks(是个有序字典,添加hook函数的顺序很重要,反向传播中会按照之前添加的顺序调用)。 -
如果用户想让梯度保存在某个中间节点的话,需要调用
中间节点的retain_grad函数(默认情况下,只有叶子节点会保存梯度值)。在调用此函数后,会往_backward_hooks字典中注册retain_grad_hook函数,当该函数被调用,传给它的梯度值会保存到中间张量的grad属性上。 -
**需要注意的是反向传播过程中
hook系统是如何工作的,往中间节点和叶子节点上添加hook是有区别的。**当往叶子节点添加hook函数,该函数就只是被添加到_backward_hooks字典中。而往中间节点添加hook函数的同时,所有在反向图中关联了该中间向量的节点都会被通知,上图中MulBackward0节点关联了张量c,即将_backward_hooks字典添加到MulBackward0节点的pre_hooks列表中,这些列表中函数都会在梯度被传递给backward函数前被调用。在注册好所有hook函数后,过一遍反向传播过程。
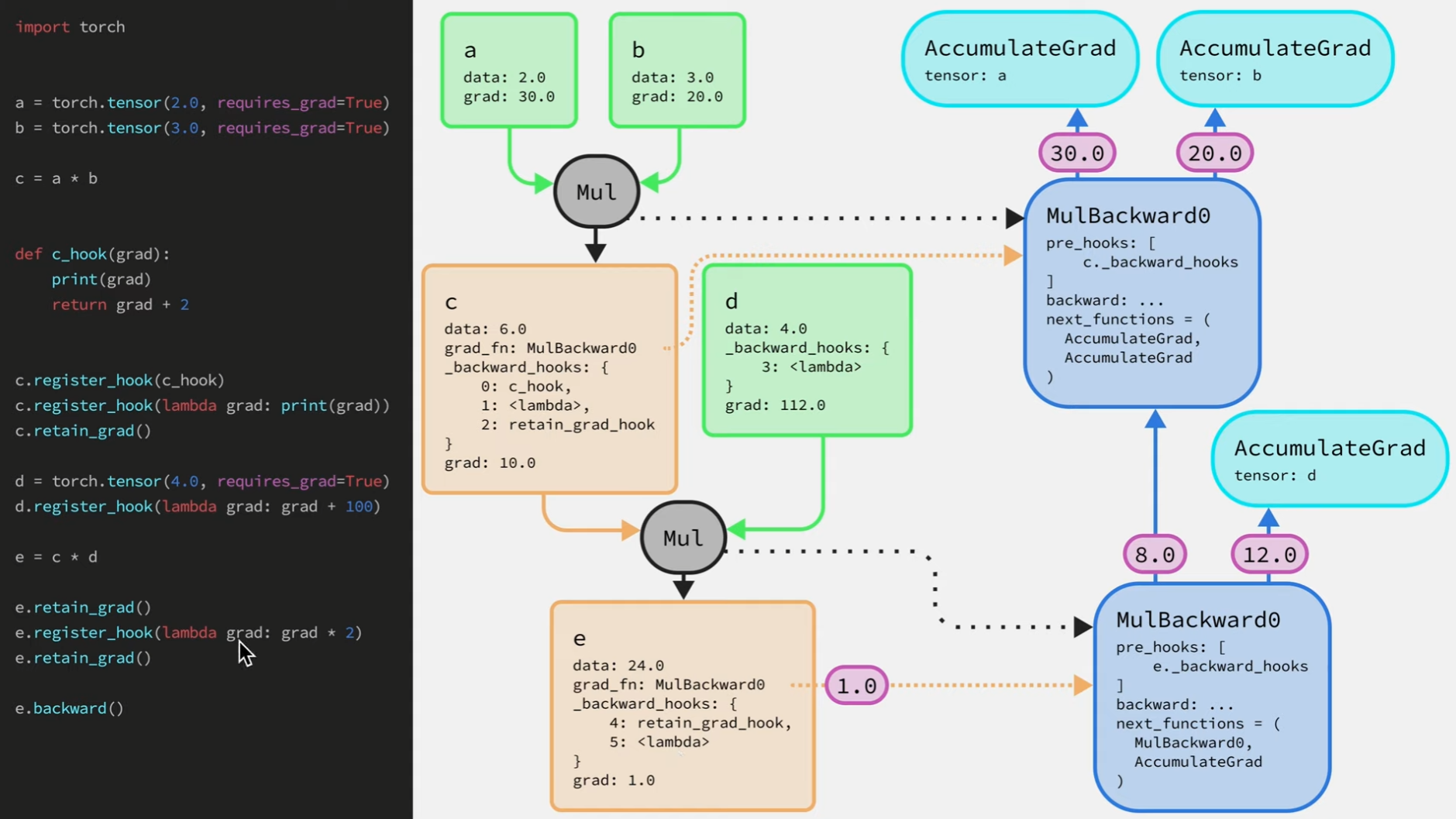
流程:1.0->MulBackward0->pre_hooks->_backward_hooks->将梯度2->backward->8,12(12会被传递给叶子张量d的AccumulateGrad节点,同时该节点会检查其所关联的张量是否有注册backward_hooks,如果注册了(d中注册了,a,b未注册),该节点会把梯度传给这些注册的hook函数处理,然后再保存到张量的grad属性上)->梯度10->backward-> …
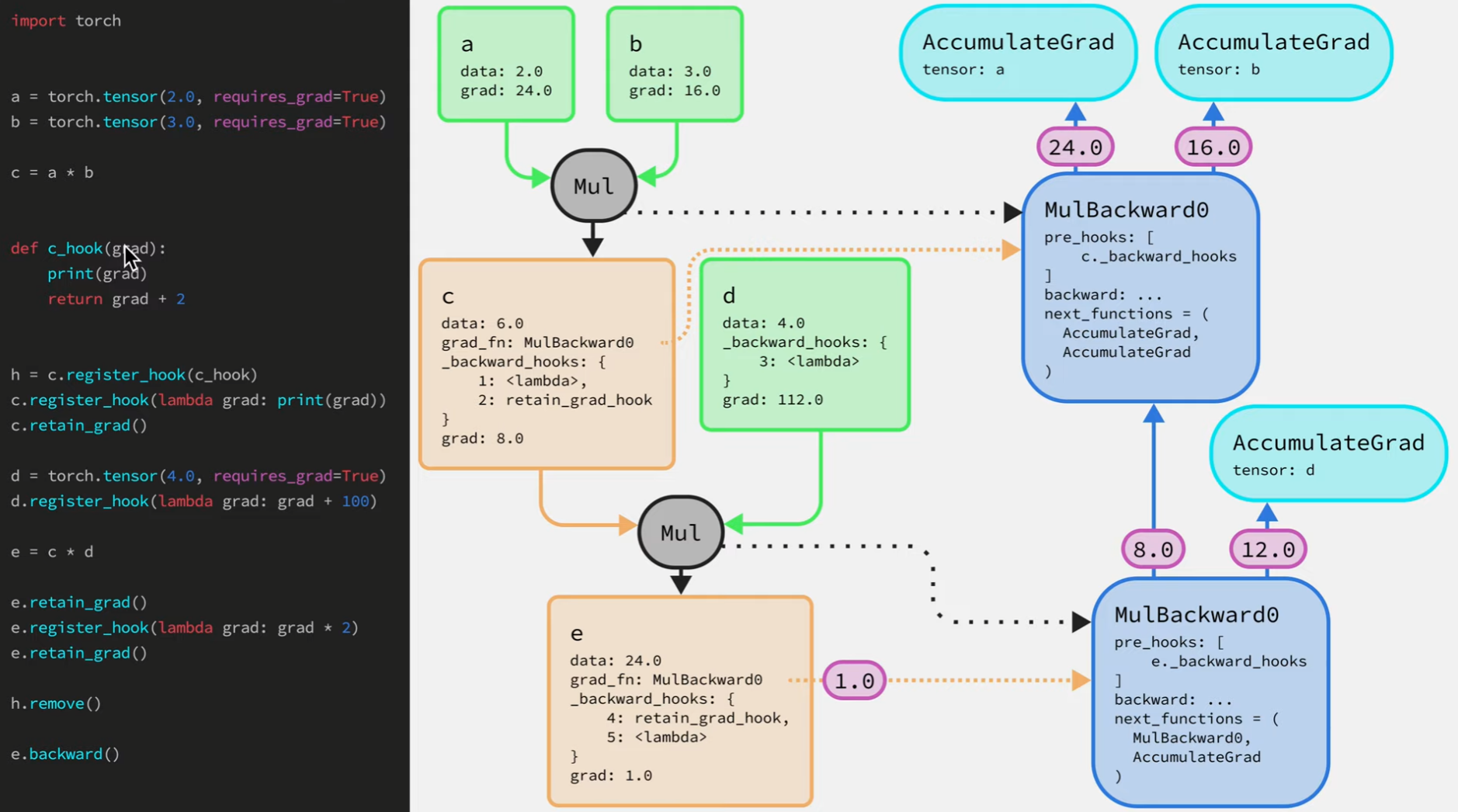
h.remove()可以将hook函数从保存它的_backward_hooks字典中移除,如上图在调用e.backward之前调用了h.remove,那么在反向传播中这个c_hook函数就不会被调用,另外要注意的是,在这些hooks函数中不要对梯度张量本身做任何修改,即不要对输入梯度做inplace操作如grad *= 100。原因是这个梯度有可能同时被传递给后向图中其他节点。
4.2 Module上的hooks
Module上的hooks函数是在forward函数调用之前或之后被调用的。下面例子实现了一个SumNet模块,其forward函数是将三个张量相加并返回结果。
1 | import torch |
- 和往张量上注册
hooks函数一样,同样可以用一个变量来保存注册hooks函数时的返回值,即hook函数的句柄(handle to the hook),这样方便后面移除hook。
1 | def main(): |
-
Module还有另一种hook,即backward_hook。register_backward_hook(backward_hook)1
2
3
4
5# args:实例、输入梯度、输出梯度
def backward_hook(module,grad_input,grad_output):
print('module:', module)
print('grad_input:',grad_input)
print('grad_output:',grad_output)
5. einsum
基本规则:
-
在不同输入之间重复出现的索引表示,把输入张量沿着该维度做乘法操作。如
"ik,kj->ij",k在输入中重复出现,所以就是把a和b沿着k这个维度作相乘操作1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20import torch
'''
a, b:
(tensor([[6, 0, 5],
[6, 4, 8]]),
tensor([[6, 5, 2, 3, 1],
[4, 8, 1, 8, 5],
[0, 6, 7, 6, 7]]))
c:
tensor([[[36, 30, 12, 18, 6],
[ 0, 0, 0, 0, 0],
[ 0, 30, 35, 30, 35]],
[[36, 30, 12, 18, 6],
[16, 32, 4, 32, 20],
[ 0, 48, 56, 48, 56]]])
'''
a= torch.randint(low=0, high=10, size=(2, 3))
b= torch.randint(low=0, high=10, size=(3, 5))
c = torch.einsum('ik,kj->ikj', a, b) -
只出现在一边的索引,表示中间计算结果需要在这个维度上求和
1
2
3
4
5'''
d: tensor([[ 36, 60, 47, 48, 41],
[ 52, 110, 72, 98, 82]])
'''
d = torch.einsum('ik,kj->ij', a, b) -
等式 右边的索引顺序可以是任意的,比如上面的
"ik,kj->ij"如果写成"ik,kj->ji",那么就是返回输出结果的转置,用户只需要定义好索引的顺序。
特殊规则:
- 可以不写包括箭头在内的右边部分,那么在这种情况下,输出张量的维度会根据默认规则推导。就是把输入中只出现一次的索引取出来,然后按字母表顺序排列,比如上面的矩阵乘法 “ik,kj->ij” 也可以简化为 “ik,kj”。
- 支持
"..."省略号,用于表示用户并不关心的索引。
1 | import torch |