What I cannot create, I do not understand. - Richard Feynman
马毅介绍了近期的工作:通过优化 MCR^2 目标,能够直接构造出一种与常用神经网络架构相似的白盒深度模型,其中包括矩阵参数、非线性层、归一化与残差连接,甚至在引入「群不变性」后,可以直接推导出多通道卷积的结构。该网络的计算具有精确直观的解释,受到广泛关注。这个框架不仅为理解和解释现代深度网络提供了新的视角,有可能地改变和改进深度网络的实践所得到的网络将完全是一个“白盒”,而随机初始化的反向传播不再是训练网络的唯一选择。
0. High-Dim Data

每一类的数据一定在高维空间中的一个低维的流形或者分布上,实际上整个机器学习就是在学到底谁是谁,找到这些结构。所有目前基于数据的AI或者机器学习都在做以下三件事情:
- 数据插值——寻找样本之间的相似关系,这体现为聚类或分类任务
- 在上一步表现良好的基础上,可以判断新的数据所属类别
- 当对以上两点理解不错的时候,可以考虑将数据表达的更好

整个网络学习过程中我们并不知道数据内在的结构是什么

很多理论希望去解释深度学习到底在干什么,其中一种是说:深度网络其实是从数据中抓取一些与标签最相关的特征,同时把不相干的特征扔掉,与具体任务强相关不通用。

- 从计算的角度来说,在处理高维数据的时候,传统信息论的统计量是无法定义的,高维数据常常是退化分布的,无法完成有效测量。
- 当数据有低维结构时,这些量在数学上甚至没有定义
很多NIPS文章提出一个理论,紧接着马上开始近似,某些量是independence开始计算,两三步后与原始信息的区别和联系都不知道了,如何提供指导。
1. 区分数据


传统聚类方法通常采用最大化相似度的方法进行,而应用在高维退化分布的数据上时,相似度难以定义。因此,我们从更基础的问题出发,为什么需要聚类划分数据?
从压缩角度,我们可以看出,能够划分的数据具有更小的空间,通过划分能够获得对数据更有效的表示。如果能找到编码长度的有效度量,就可以设计相应的优化目标。
熵是度量编码长度的工具,但在高维数据上,熵的测量非常困难,马毅教授采用率失真理论来度量这样的表示,提出了编码长度函数(Coding Length Function)

上述公式相当于给一组数据就输出其需要的bits存储空间
有上图的度量后,我们就能描述聚类或划分的现象,即划分前的数据所须的编码长度,大于划分后的编码长度。这样的划分不需要标签,而是可以通过一些贪心算法,比较不同划分之间的编码长度,获得使划分后编码长度最小的划分。结果展现了这样的方法有非常好的聚类效果,能够找到全局最优的划分,并对离群点非常鲁棒。
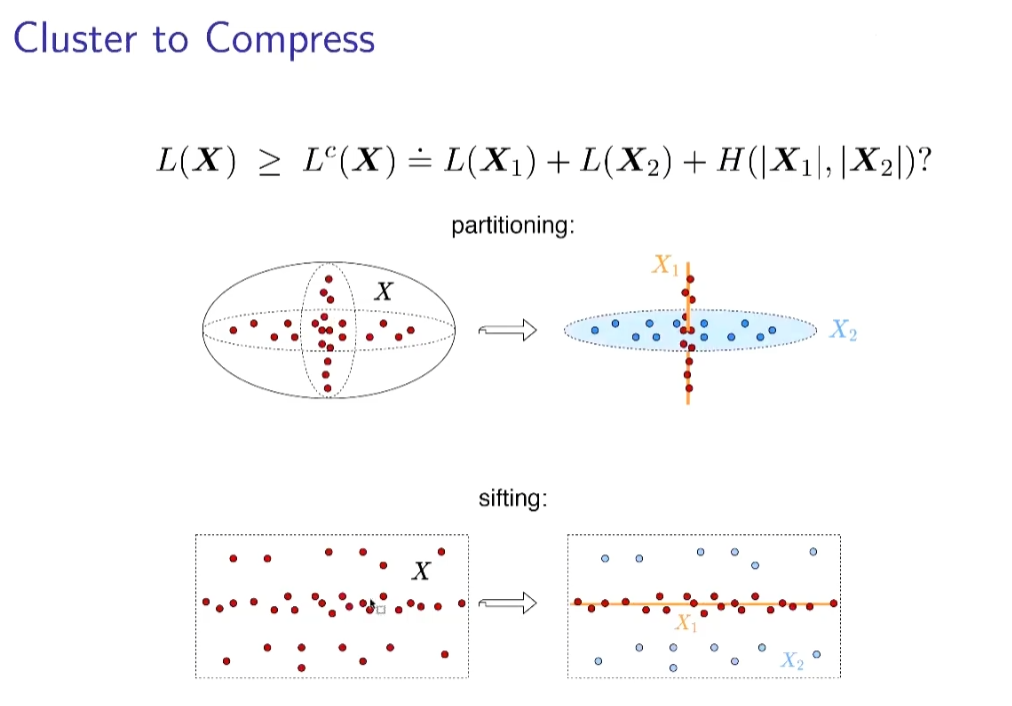
整个的数据分类就变成一个压缩的问题,要分开的话,其分开后的压缩的量用的bits最少

这个量非常神奇,你可以把数据每个点都分开,再两两融合(如果可以省bits),可以得到一个pwm算法
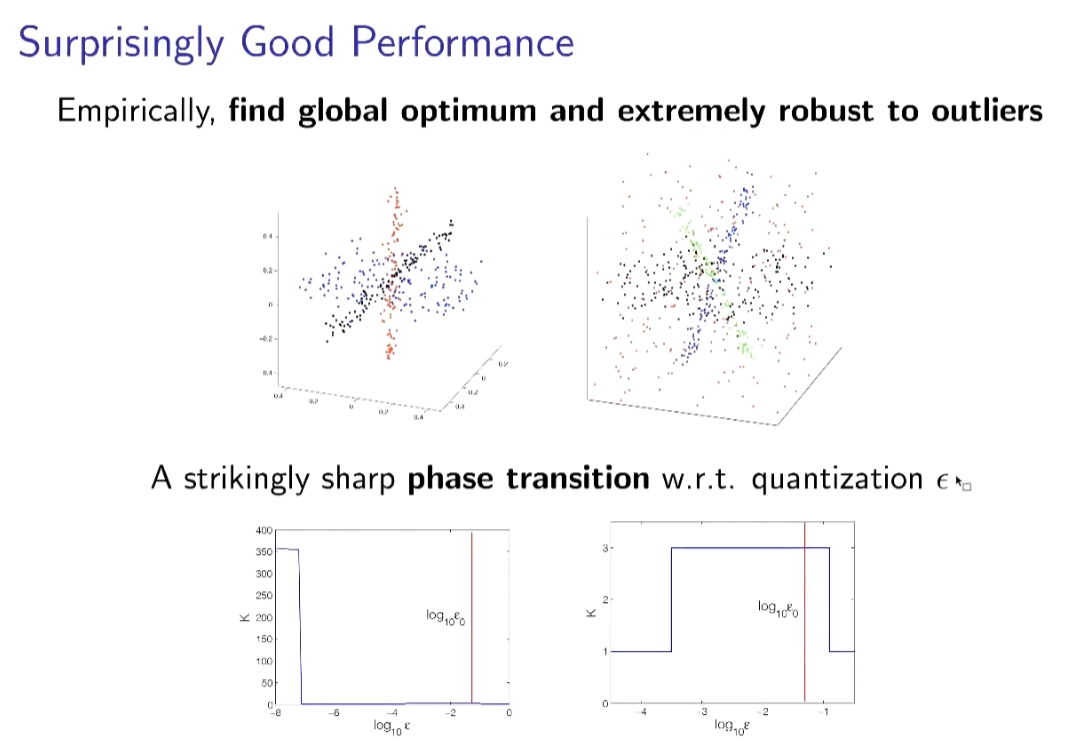
神奇在数据有很多的噪声和异常值的情况下,都能找到低维结构

仅使用数据压缩的算法,就取得了当时最好的分割效果
2. 划分新数据

当数据有低维结构时此公式不适用,教课书中教的是上图公式的做法,但实际应用中并不用统计教科书中的方式。

不适用应该怎么办呢最大似然估计不work,又回到编码量。如果要对某个样本分类,那么包含其后那一类相比其他类的编码量应该是最小的。
同样的方法可以应用于分类任务,通过比较将新数据划分到不同类别增加的编码长度,选取使编码长度增加最少的类别,作为该样本最合适的分类,这种方法依旧来源于最小划分后编码长度的理论。这种方法可以理解为,将新样本划分到合适的类别分类后,所带来的存储开销应当最少,通过正确分类,可以得到最优的表示效率。结果显示,比较传统方法,MICL能够找到更加紧的边界,并且与分类不同的是,其决策边界更接近于数据本身的结构特征。

整个过程可以通过数学证明
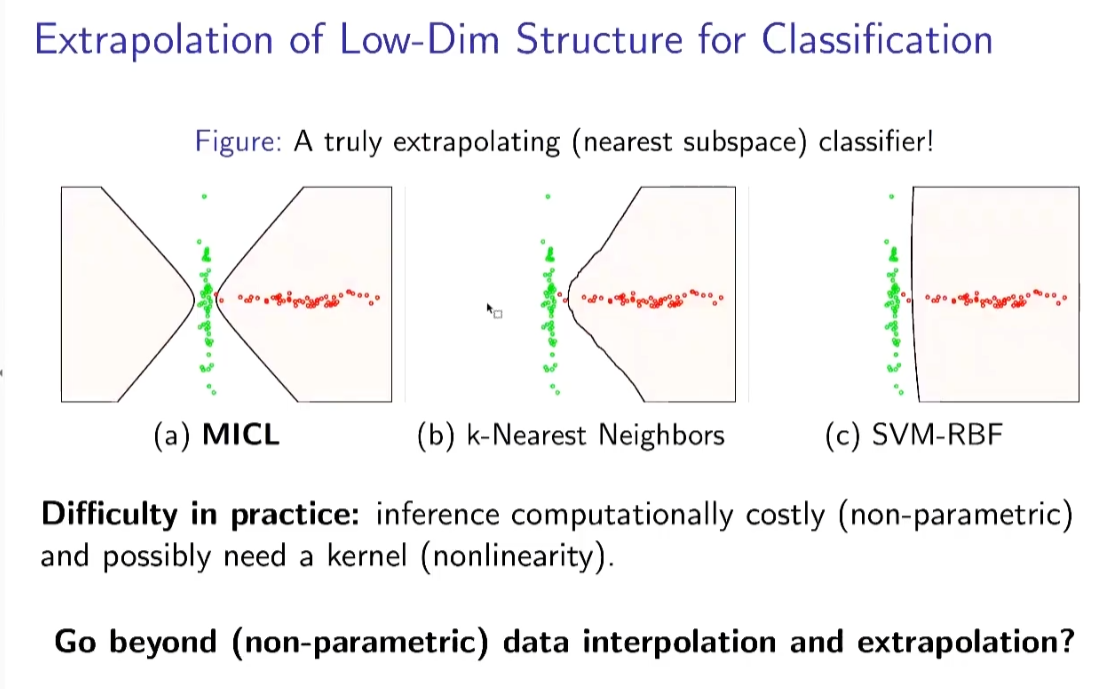
通过简单的分类,已经学到了数据的低维结构,但只是对低维子空间和高斯分布很准,当数据有非线性结构不适用。
3. 表征数据
在完成了 Interpolation(聚类)与 Extrapolation(分类)后,从压缩的视角,还能够实现对数据的表示。当数据符合某种低秩结构时,优秀的表达的目标可以被理解为,最大限度地学习到该结构特征,即,在让同一结构样本靠近的同时,使样本表达能力最大;同时,将不同结构数据间的差异尽可能清晰地体现出来。



如何判断变换后特征的好坏呢?通过衡量整体和局部平均编码量来衡量


同类(局部)越近越好,不同类(整体)越远越好
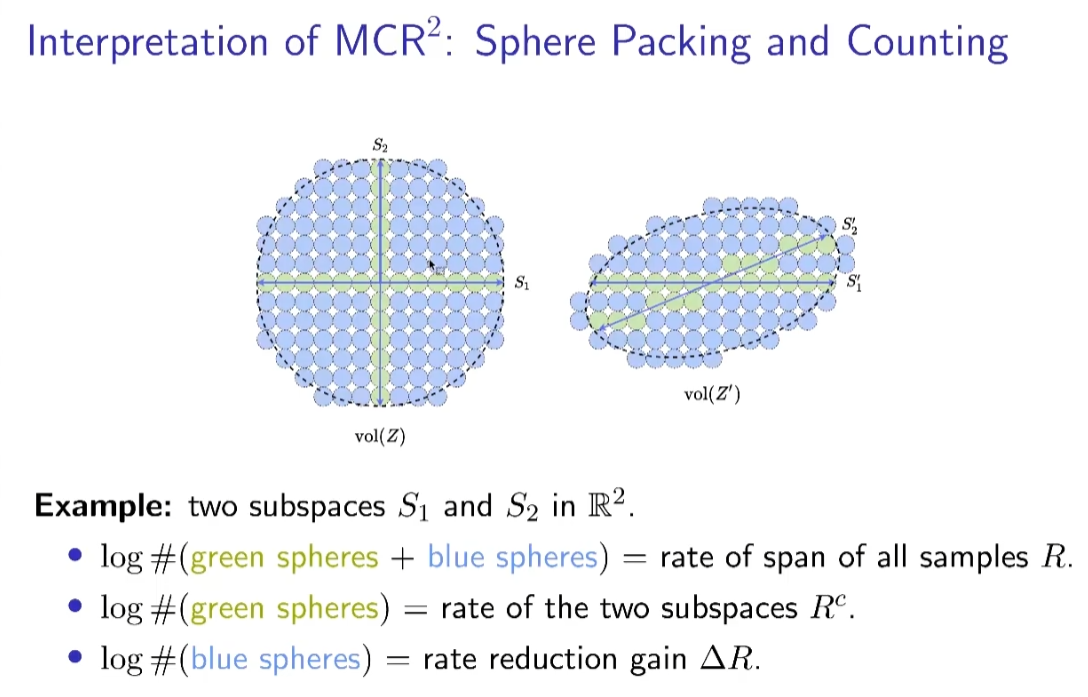
左优于右,蓝色球数量多。为了使不同范围的样本进行比较,针对每个样本需要进行归一化操作。这与归一化的通常理解相符,使模型能够比较不同范围的样本。

在宽泛的条件下,数学上可以证明当特征达到最大编码量的时候,可以证明每类的特征,彼此是正交的;每类的特征可以把子空间占满。
4. 实验(MCR取代Cross Entropy)
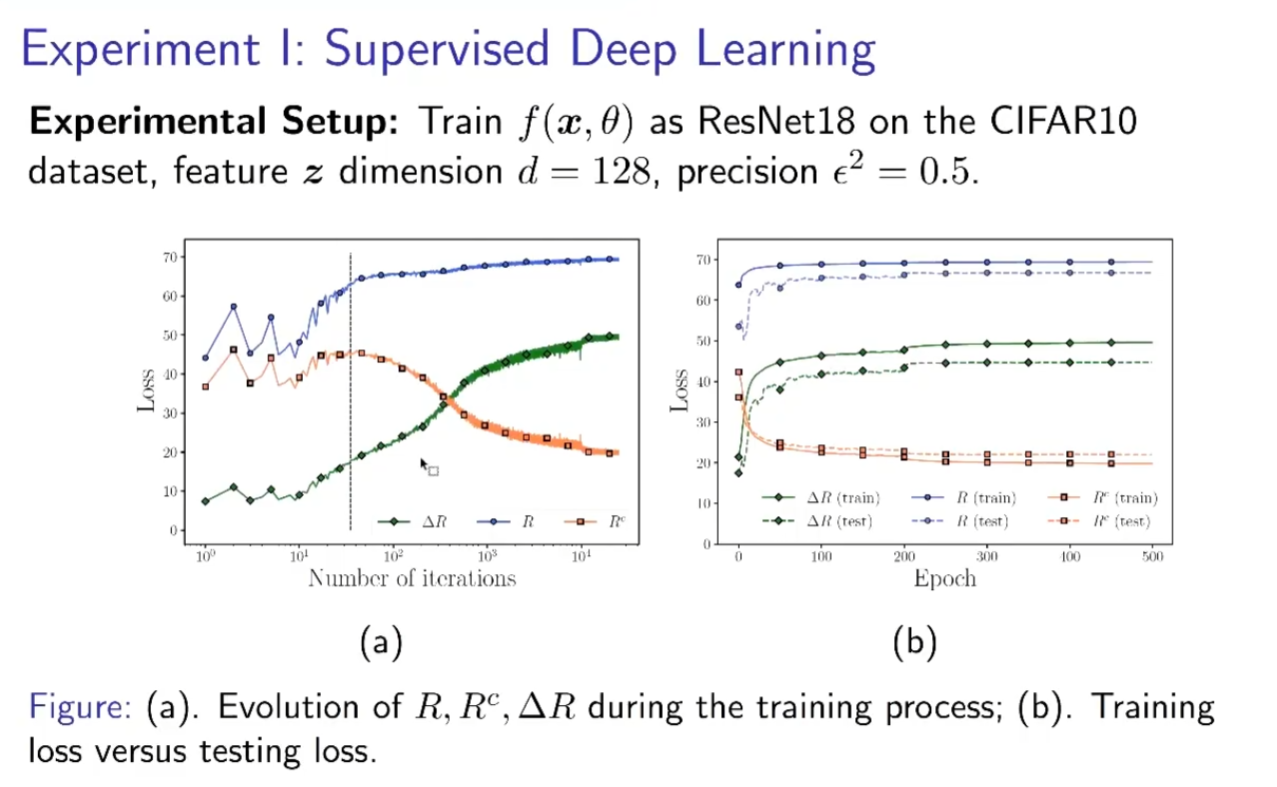
训练过程中的三个量是在物理、几何和统计上意义严格的量,整体的Vol在增长,局部的Vol在压缩,差值在增长。
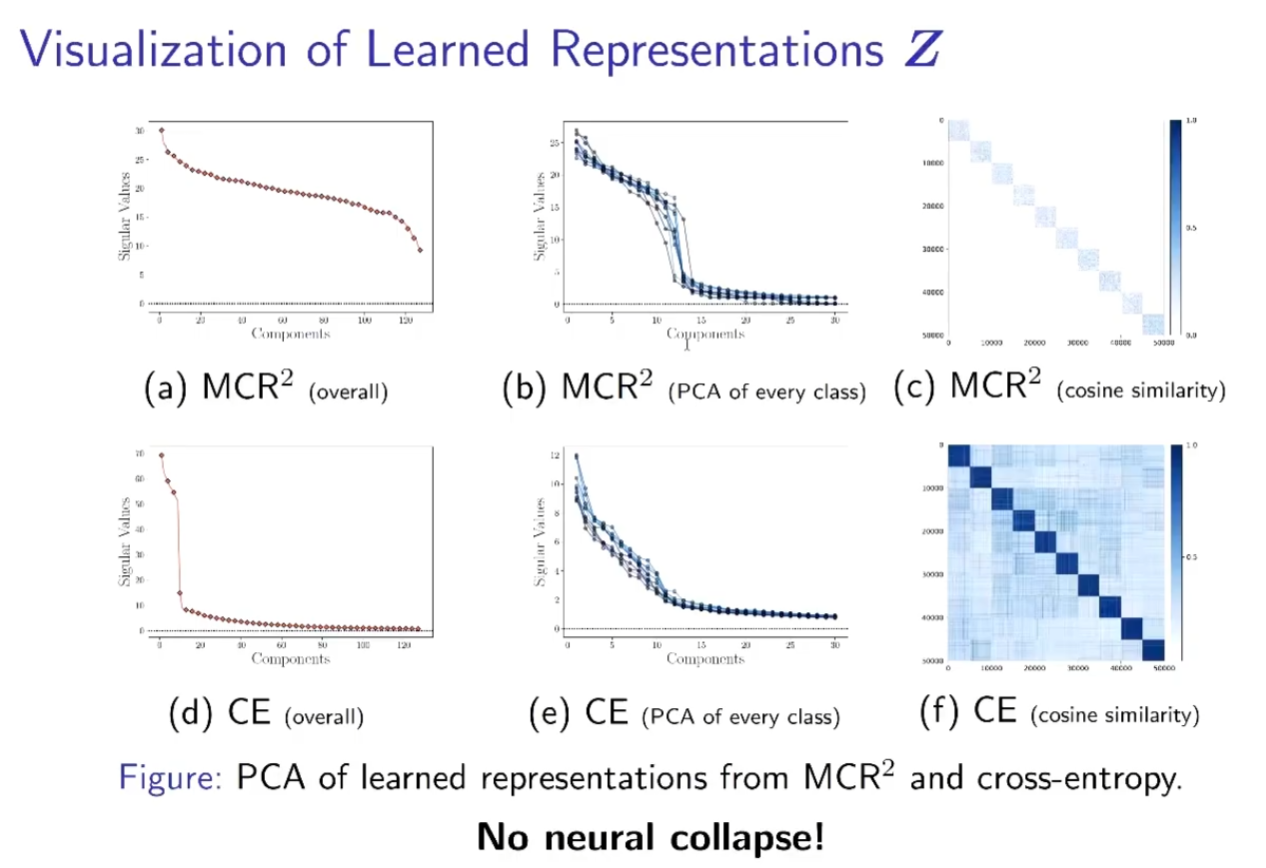
不同类的特征完全正交,每一类的特征均匀的分布在各个子空间上。
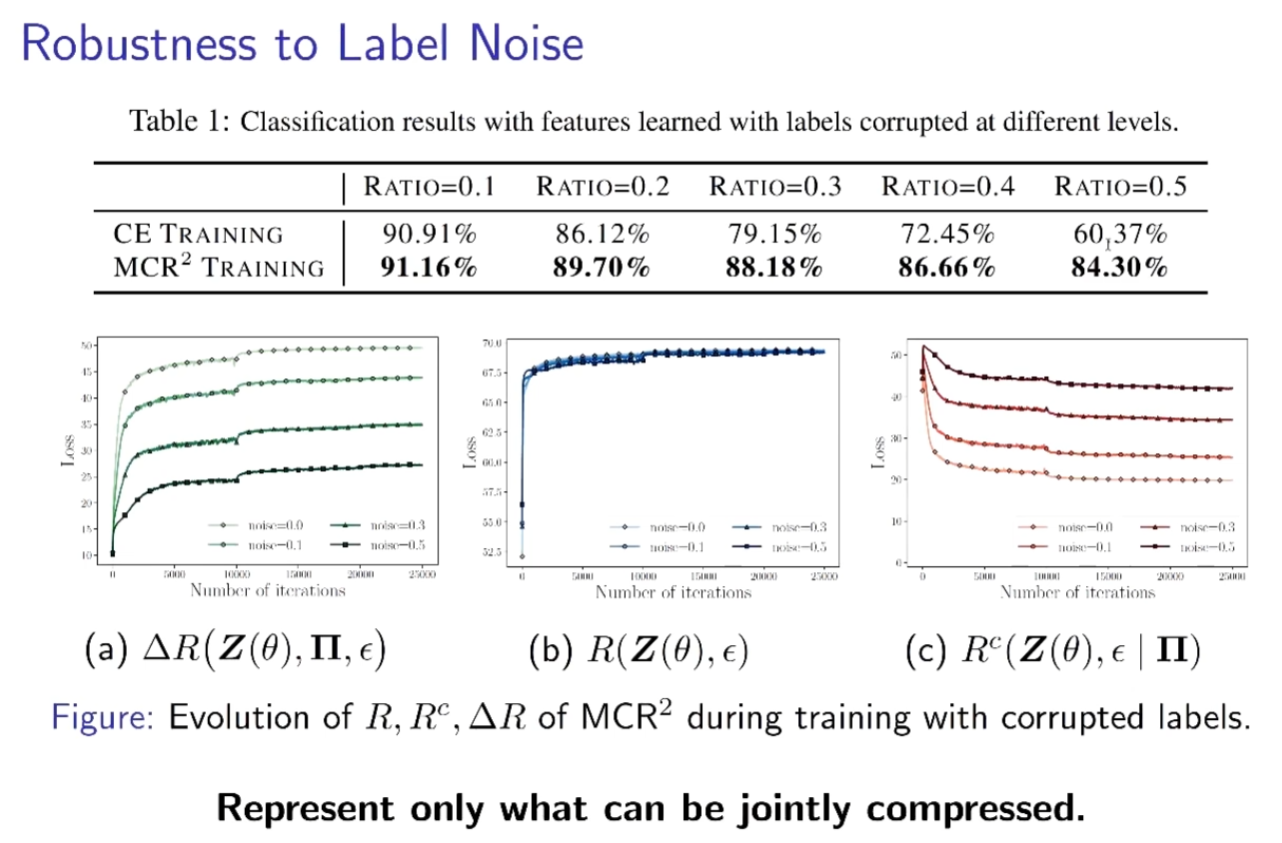
目标函数不再拟合label,从整体去学习特征,鲁棒性很强
5. 本质是什么


这是个非凸的问题,我们的目的是研究什么样的Z能优化这个问题,不管是deep learning或是其他方式。神经网络告诉我们当遇到一个很难的问题时,其他做不了可以做梯度下降,训练一下调一调。

对该目标求梯度后,获得了两个操作矩阵E、C,所求梯度就是其分别与样本乘积的和。

而观察E、C两个操作矩阵,会发现其与样本乘积的结果天然带有几何的解释,即矩阵作用于所有的样本数据上,和其他的矩阵作用于不同类的数据上。当使用其他的数据对每个数据做回归得到的残差,就是
因此,若需要扩展样本空间的大小,只需加上E与样本相乘获得的残差,若要压缩各类别子空间的大小,仅需减去与C进行相同操作的结果。
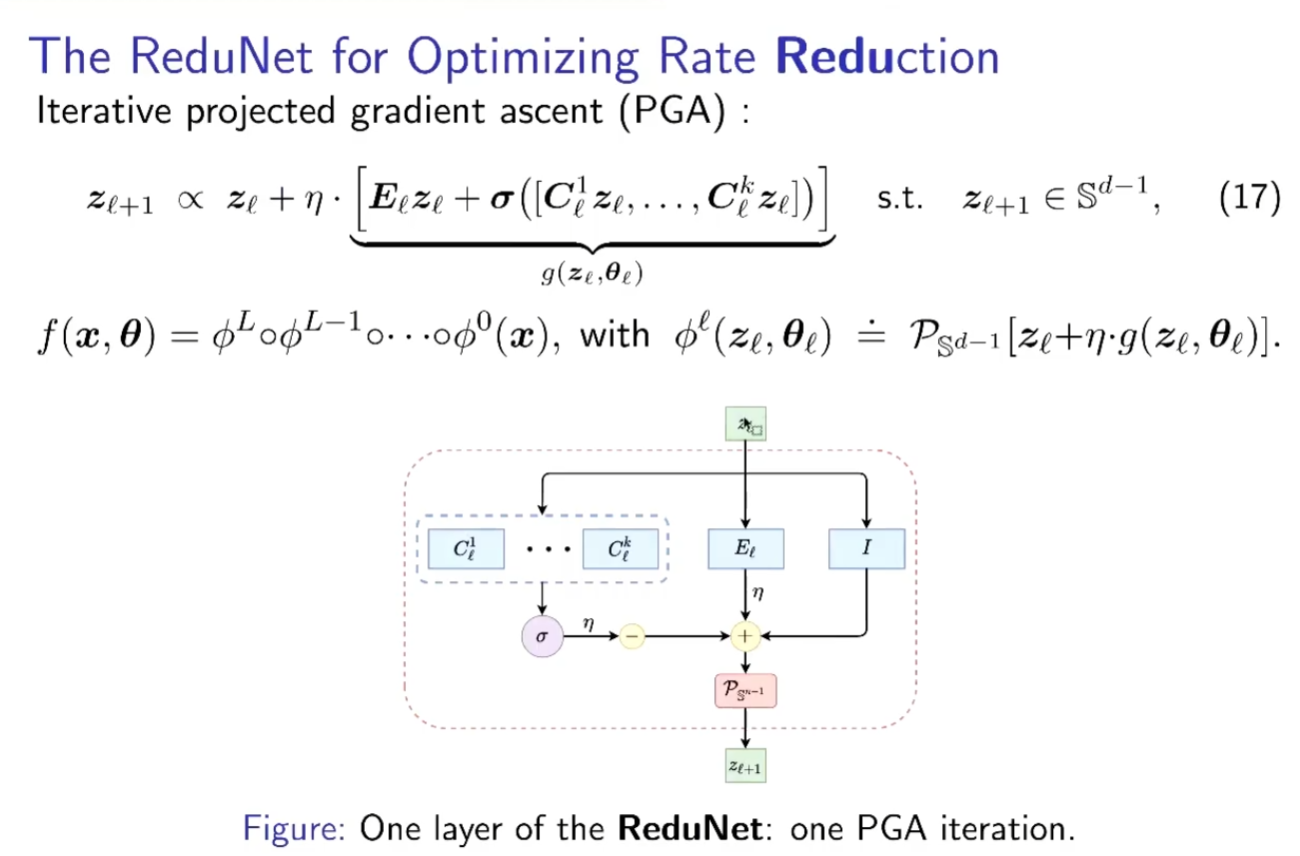
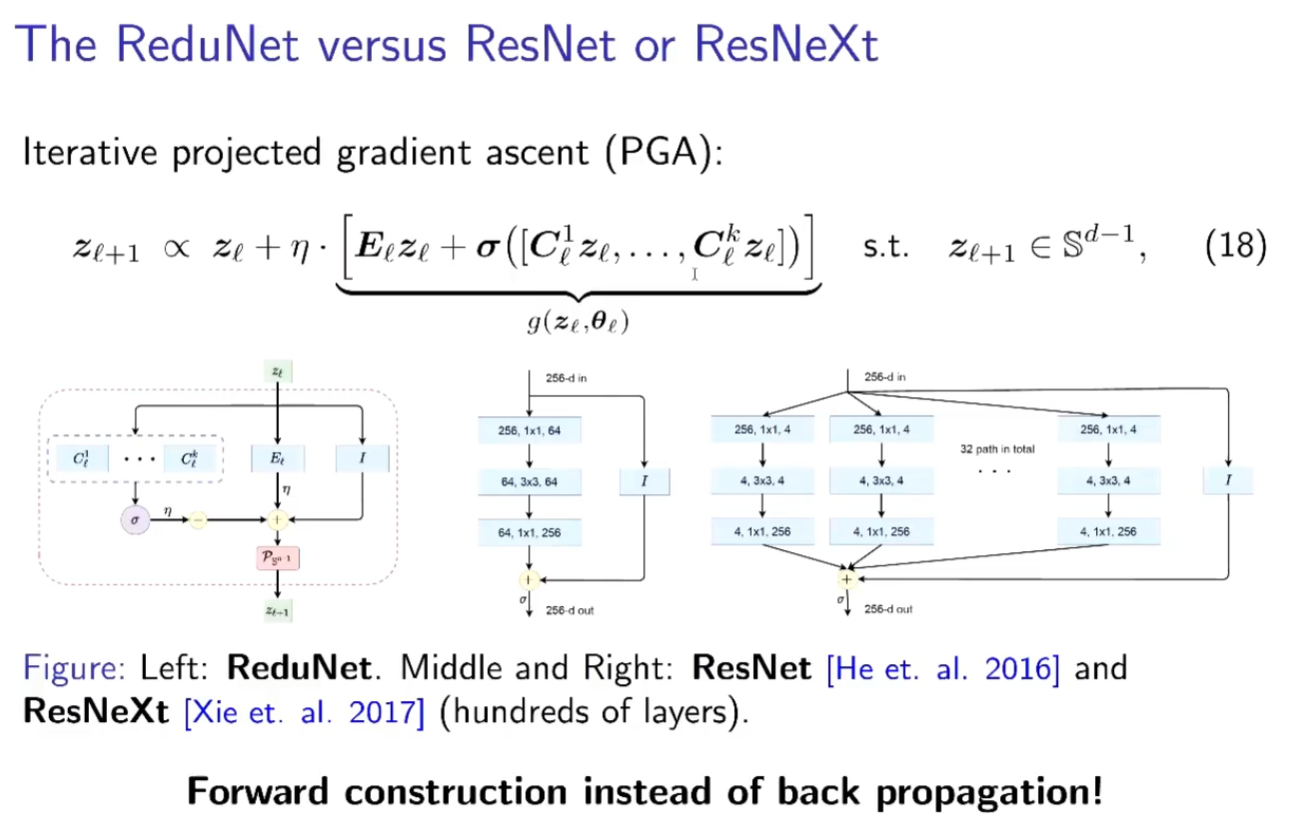
每个EC、CZ都是自回归的残差。对比常 用的神经网络结构,可以发现其与ReduNet有许多相似之处,例如残差链接,C的多通道性质,非线性层等。同时,ReduNet所有参数均能够在前向传播中计算得到,因此网络无需BP优化。

通过引入组不变性,将cyclic shift后的样本视为同一组,每次将一组样本编码到不同低秩空间,ReduNet可以实现识别的平移不变性。同时,类似卷积的网络性质也随之而来。在引入平移不变的任务要求后,网络使用循环矩阵表示样本,因而在与E,C矩阵进行矩阵乘时,网络的操作自然地等价于循环卷积。在压缩数据的过程中,梯度下降中的算子自动变成卷积。

求逆计算使得通道间的操作相互关联。上述计算还可以通过频域变换来加速计算效率。
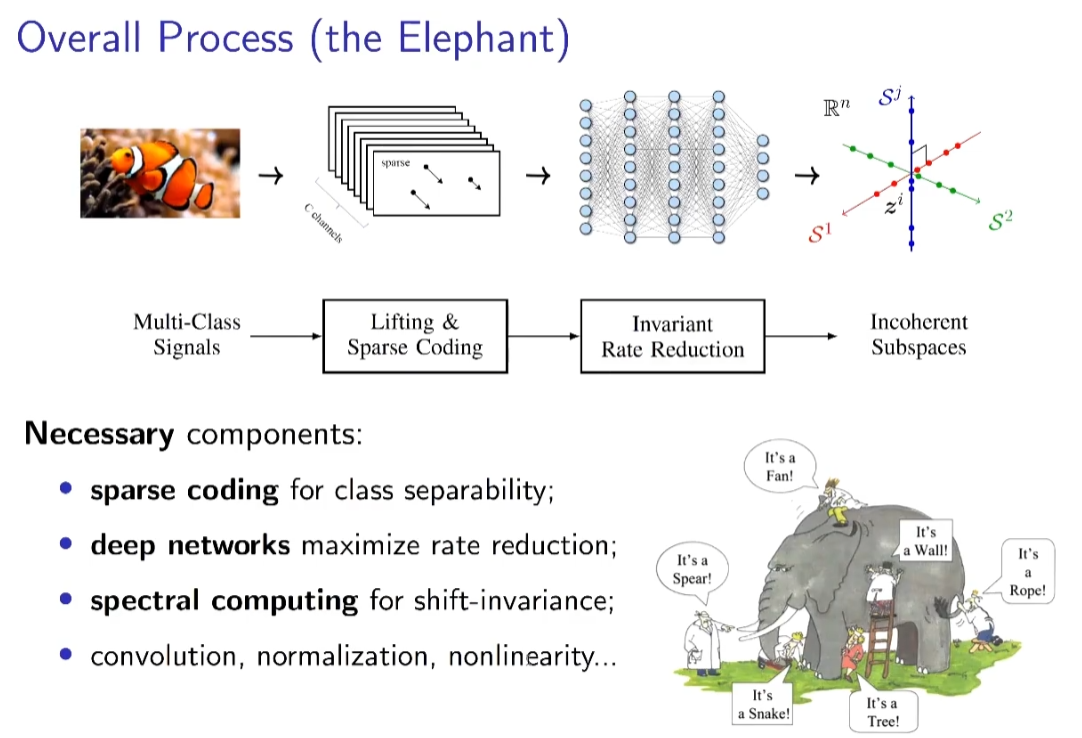
整个优化过程中自然的出现了神经网络中的提出的种种算子。尽管上文中算法有诸多变化,其核心都是基于“压缩”的概念。 聚类,划分,表征,这些学习任务都可以被表述成压缩任务。我们希望学习到样本的知识,是期望能够更高效地表示样本,因此我们学习类别,提取特征,抽象概念。 MCR^2 原理基于率失真理论,描述了划分和压缩的过程,并能够基于压缩,完成包括聚类,分类,表示学习,构造网络等等任务,体现了作为学习的一般原理的泛用性能。

QA:
每个神经元可能是原始高维空间中的一个切割平面 ,新来的数据和切割平面去比到底在切割平面的哪一边,一个神经元的输出可以得出属于哪一边,相当于encoding;可以在这个高维空间中一直切,切到一定的程度,对于任何input都可以encoding,可以基本知道这个点在高维空间中的位置。神经元的数学模型可能就是高维空间中的切割平面,用来做encoding,每一层的个数相当于数据的内在结构的维度。第二层的神经元相当于使近的更近,远的更远,后续层相当于优化迭代的次数。网络是前向学习的,即使只有少量样本就能学到很好的参数,学习过程中不用大量的资源。
