JPEG 不可思议的压缩率
以JPEG图像压缩算法为例,讲述信号处理的核心思想和主题(还讲了颜色空间、
YCbCr、色度子采样、离散余弦变换、量化和无损编码等细节。)
引子
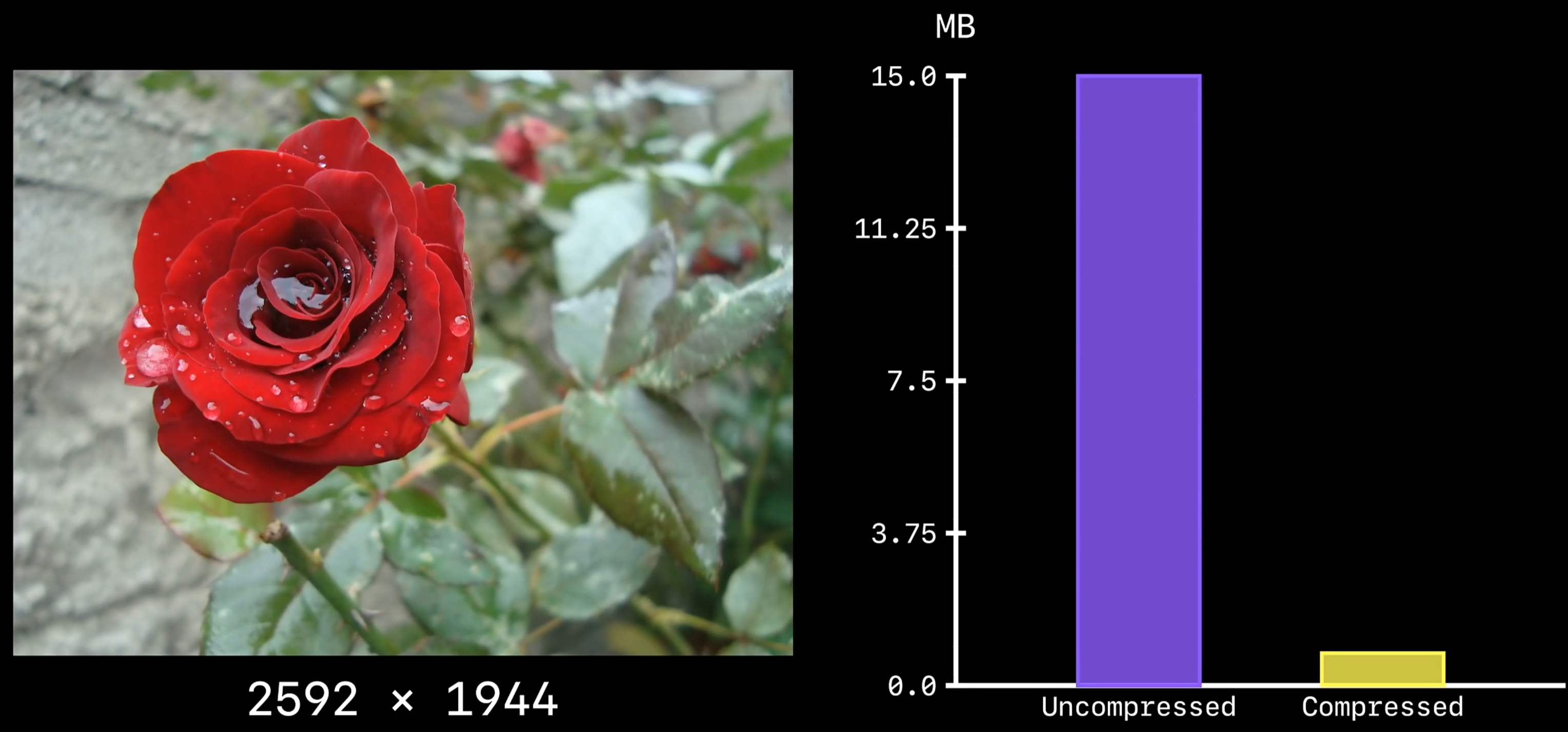
核心问题: 图片压缩过程中哪类信息可以去除,怎么去除
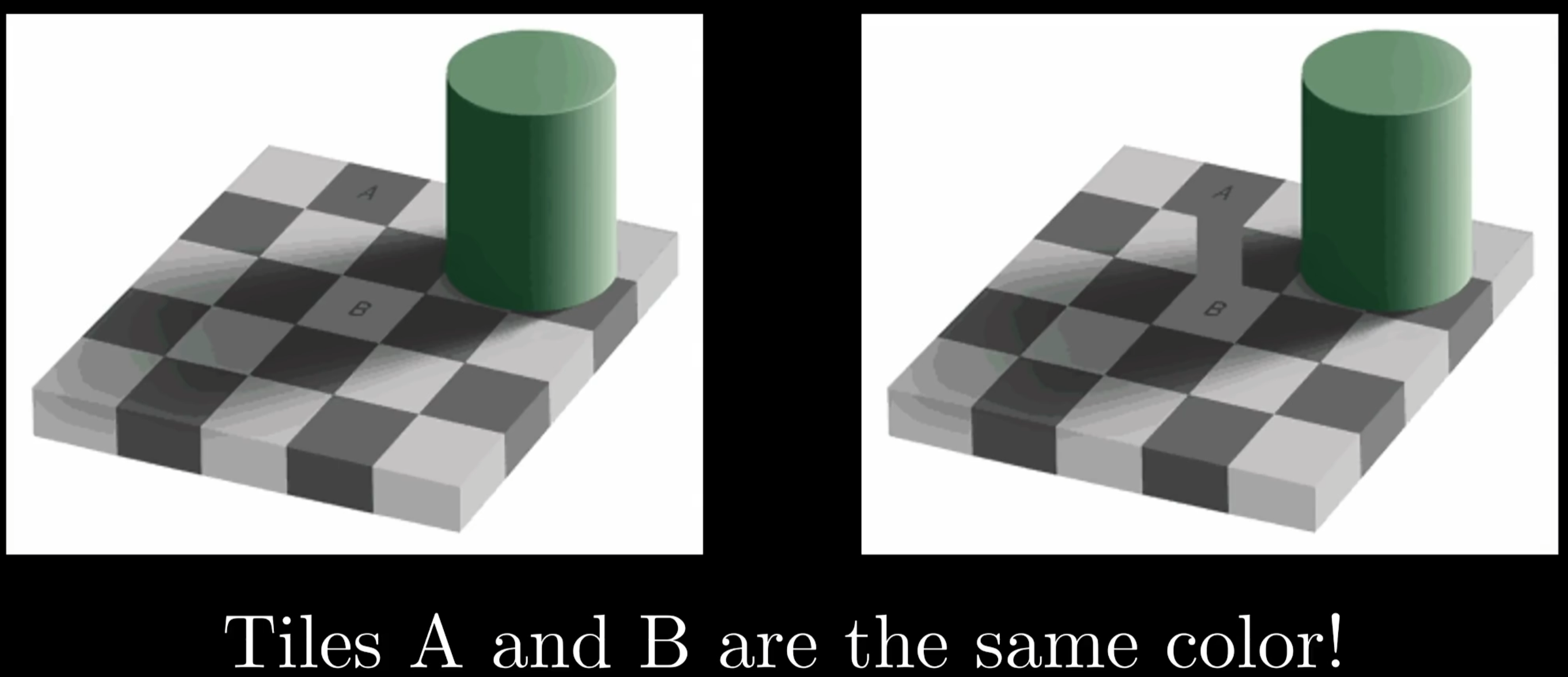
科学家发现人眼对亮度更敏感对颜色没那么敏感——JPEG压缩方案考虑了这个特点——想要知道怎么做必须深入探索色彩空间领域。


RGB色彩空间有个特点:如果沿着对角线走从原点走到(255,255,255),就能得到逐渐变亮的颜色,这些点构成的线定义了所有可能的灰阶颜色,这是衡量亮度最直接的方式。将亮度独立出来的想法是另一个色彩空间的基石YCbCr ,Y分量衡量的是图片的“流明”或亮度,Cb和Cr存储的是颜色信息。Y可以视为一个单独的纵轴,值越大表明亮度越大。JPEG使用的这种色彩空间的原因是让我们能直接调用最适合人眼识别的颜色。


由于人对亮度敏感度高,其中一个压缩原图的思路就是缩减Cb和Cr分量的采样数,但把亮度分量全保留。这个技术被称为“色度下采样/色度抽样”。
色度下采样/色度抽样

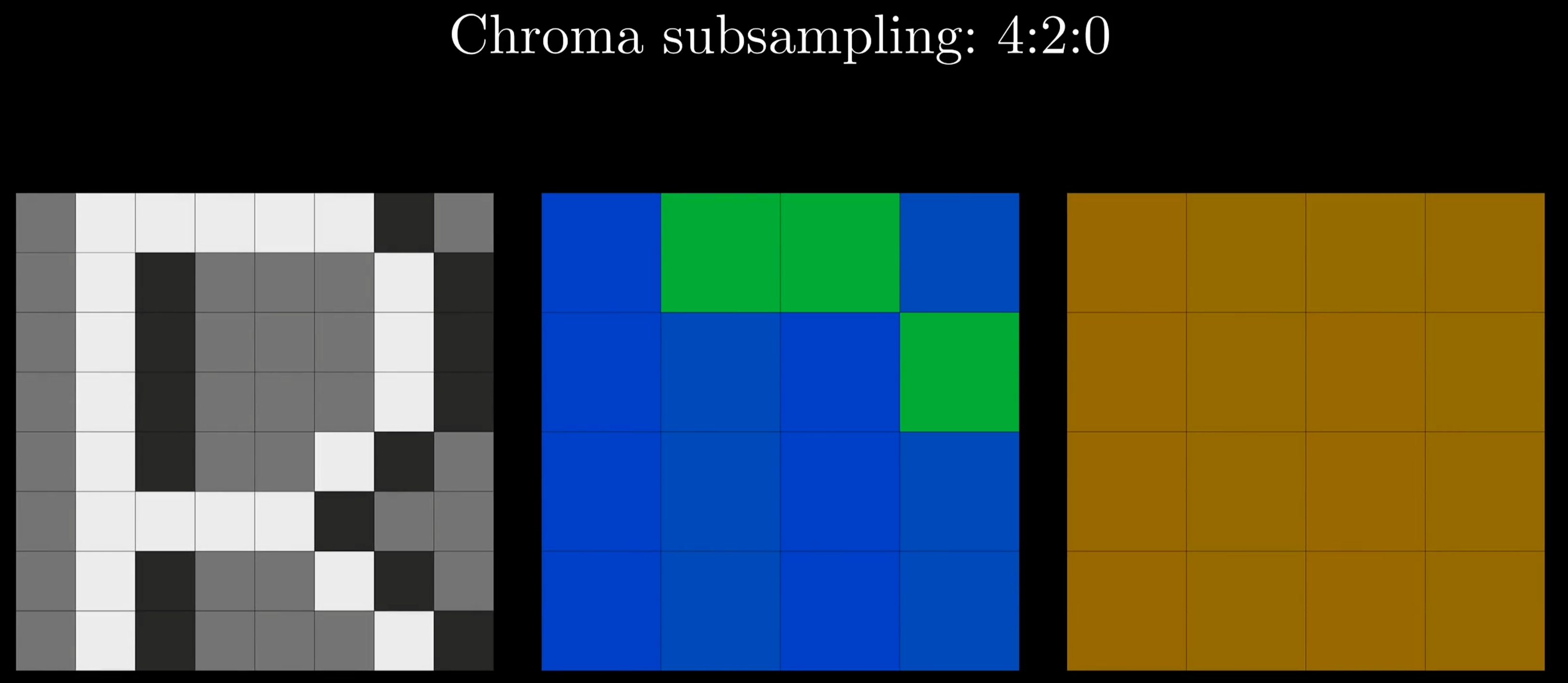
色度下采样的具体操作是对原图种四个像素点求平均得到一个值;色度抽样通常选左上角像素值代表整个2×2区域的颜色,待色彩分量的采样数缩减后就可以和亮度分量合并如上右图所示。在这里色彩分量保持16个像素,这就得到了抽样后的图像。

至此距离JPEG 95%的压缩率仍有距离,需要考虑其他方面

Y
下面的压缩环节我们关注Y通道,本节的核心原理同样可以用于色彩分量
DCT概述
我们需要以完全不同的视角来看待图片,有一个看待图片的角度是将图片视作“信号”
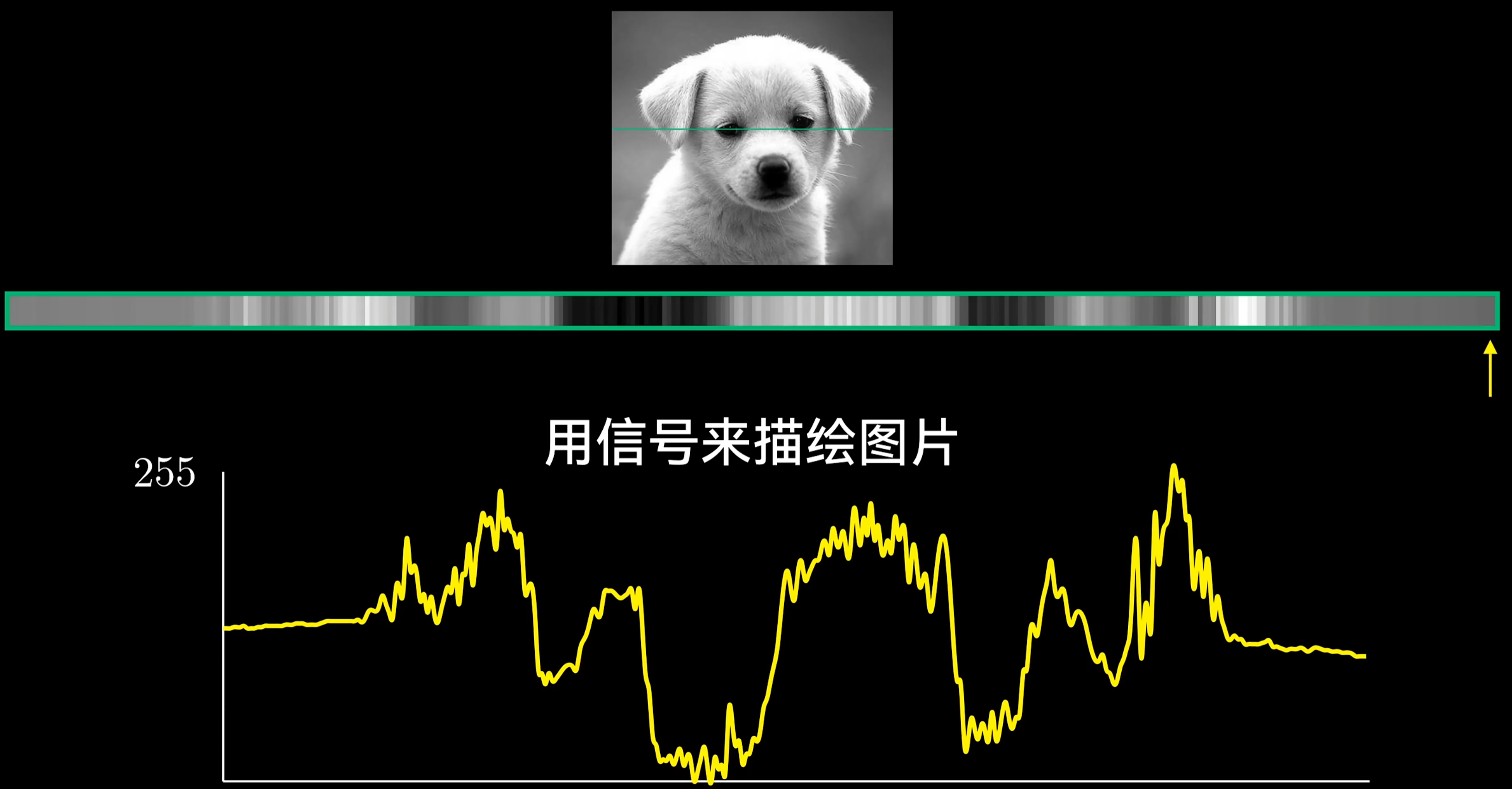
取出图片中若干像素构成的一行,使我们得以讨论图片里的“频率分量”
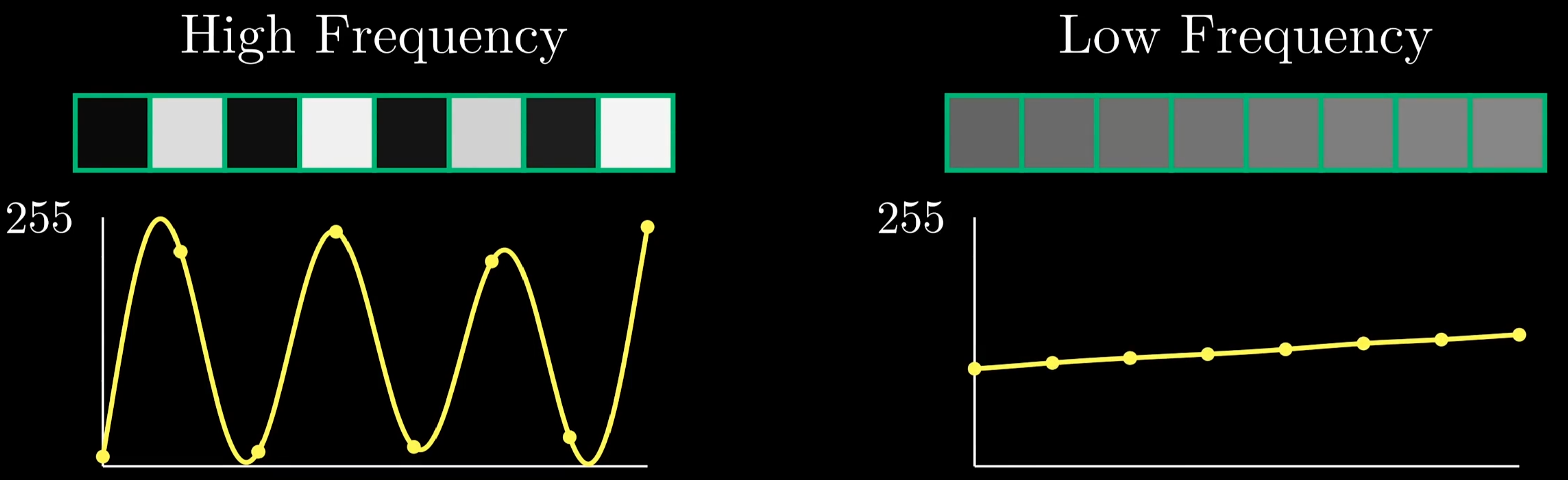

人类视觉系统通常对图片的高频细节不敏感,因此JPEG会有策略地去除图片中不太重要、较少见的高频信号,达到更大的压缩率。那么如何提取频率分量呢?
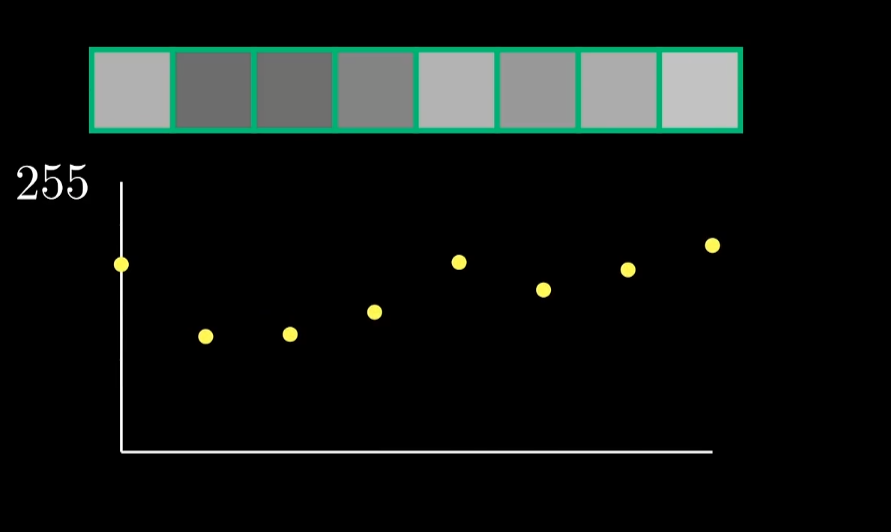
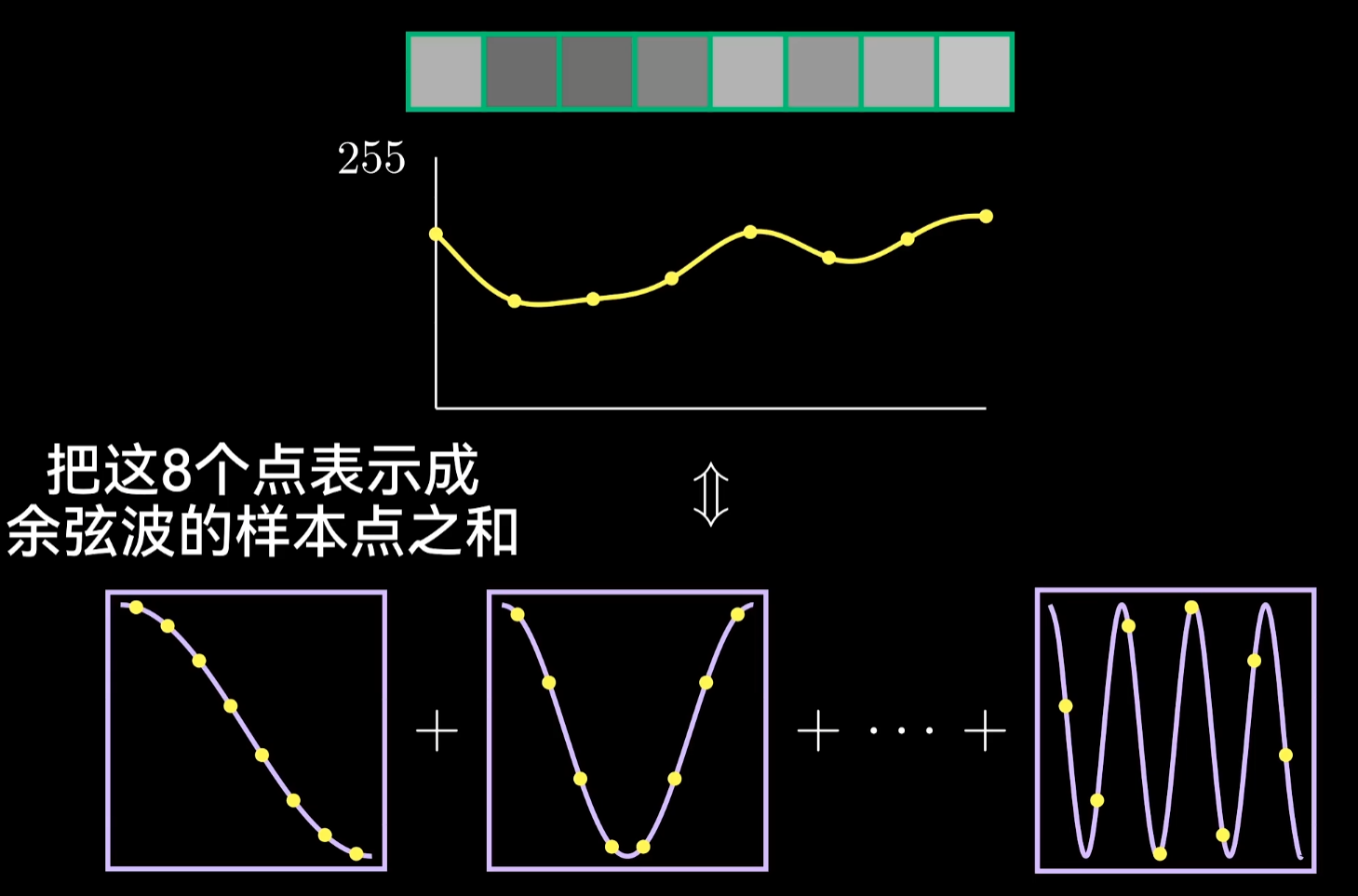
先将这8个像素当成是某种信号,DCT将原始信号的样本点作为输入。
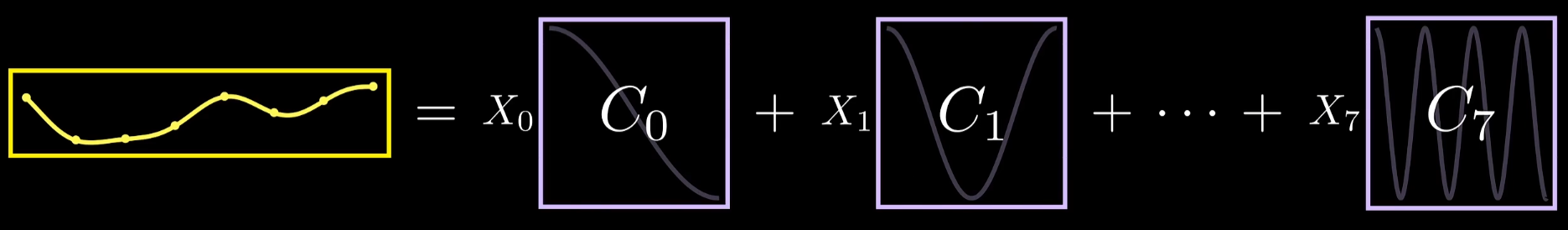
用“系数”来描述DCT的输出,这些系数描述了组成原始信号的不同频率余弦波的权重 。本质是求出某个特定的余弦波应在信号里包含多少。
可以把这个过程类比为将复杂的信号拆分成简单余弦波的加权求和,**那么到底使用了哪些余弦波,波如何和图中的像素建立关联?**以下取cos(x)为例
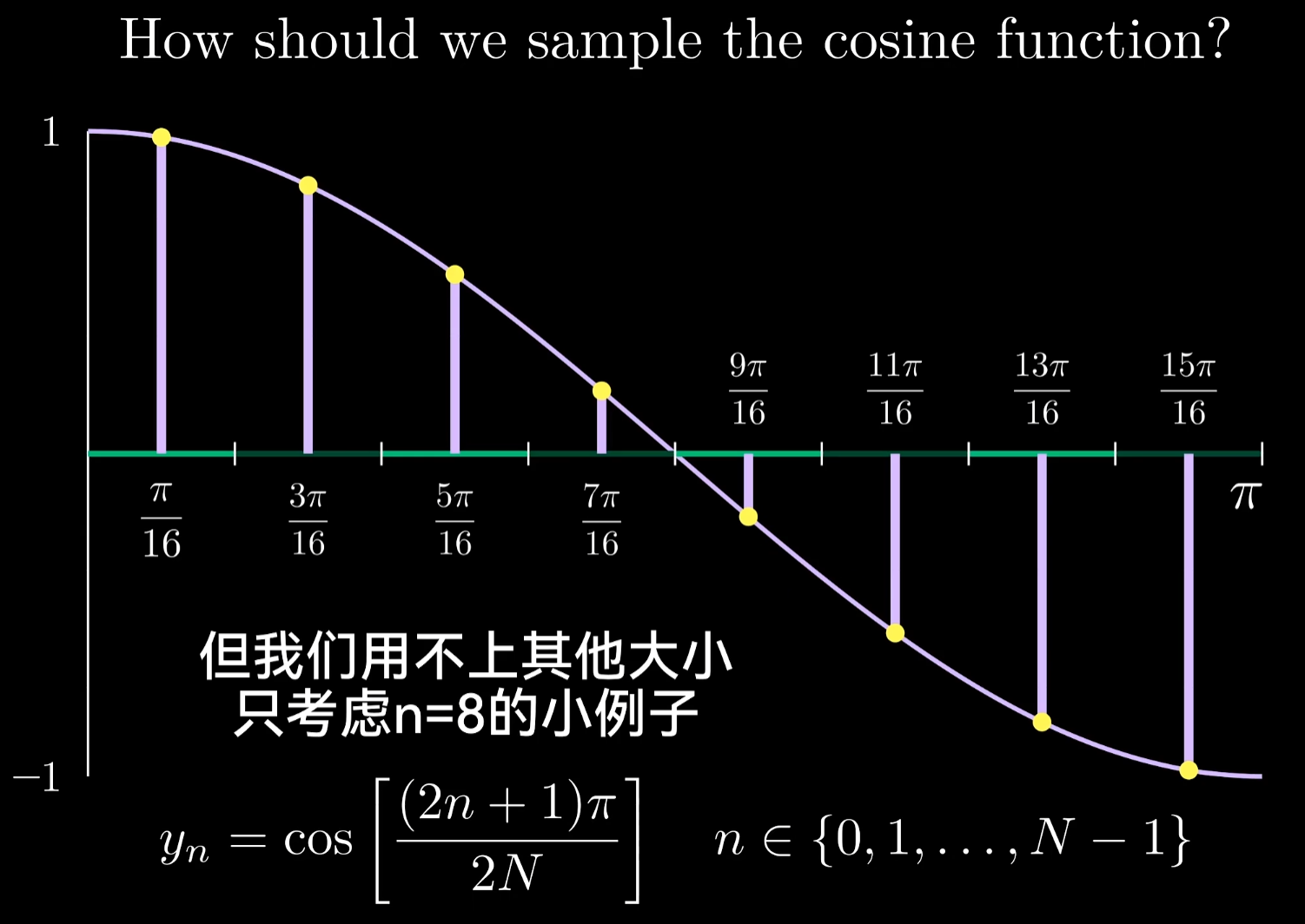
为了与之前的例子保持一致,我们需要在余弦波中采8个点做样本
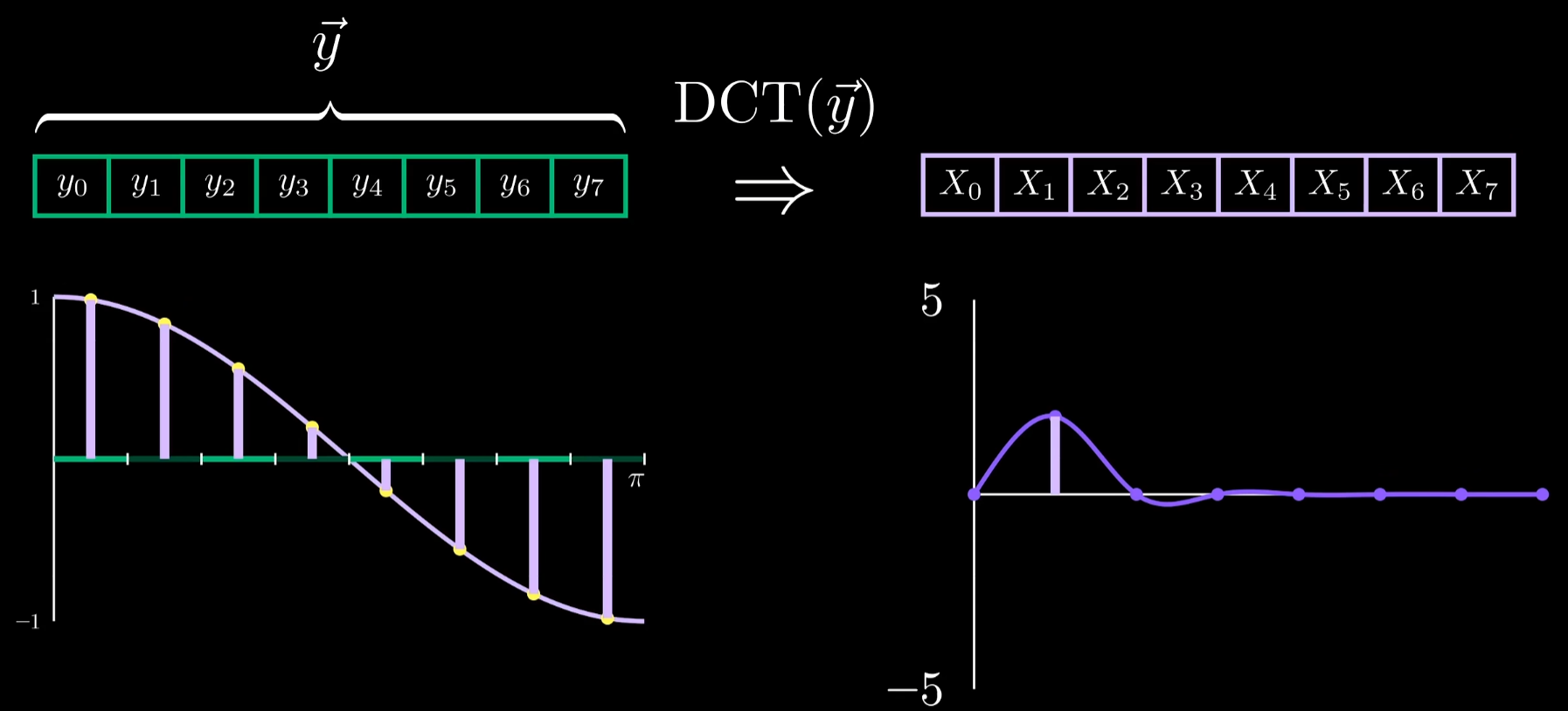
输出表明对输入有贡献的余弦波只有一个,看似合理因为此时的输入本身就取自一个余弦波。改变余弦波的振幅发现DCT系数X1同比变化,说明其实际担任了余弦曲线中权重的角色。那么如何将其与图像联系起来?
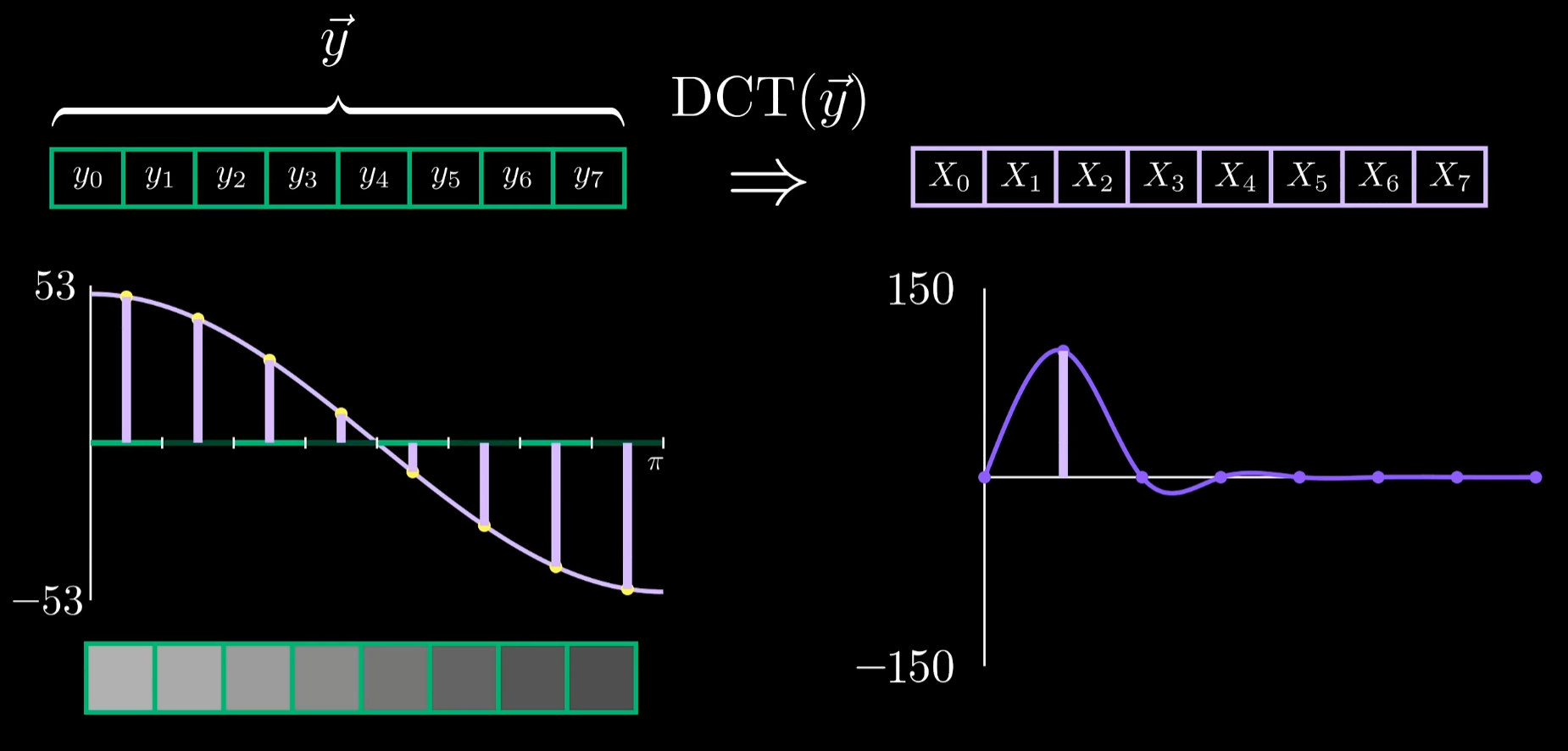
构建余弦波到图像的映射: 要让余弦波到图像的映射更合理可以把像素值平移128个单位(0,255)->(-128,127)此时,像素变化的大小和方向便反映到原始余弦波的振幅上即DCT的系数。
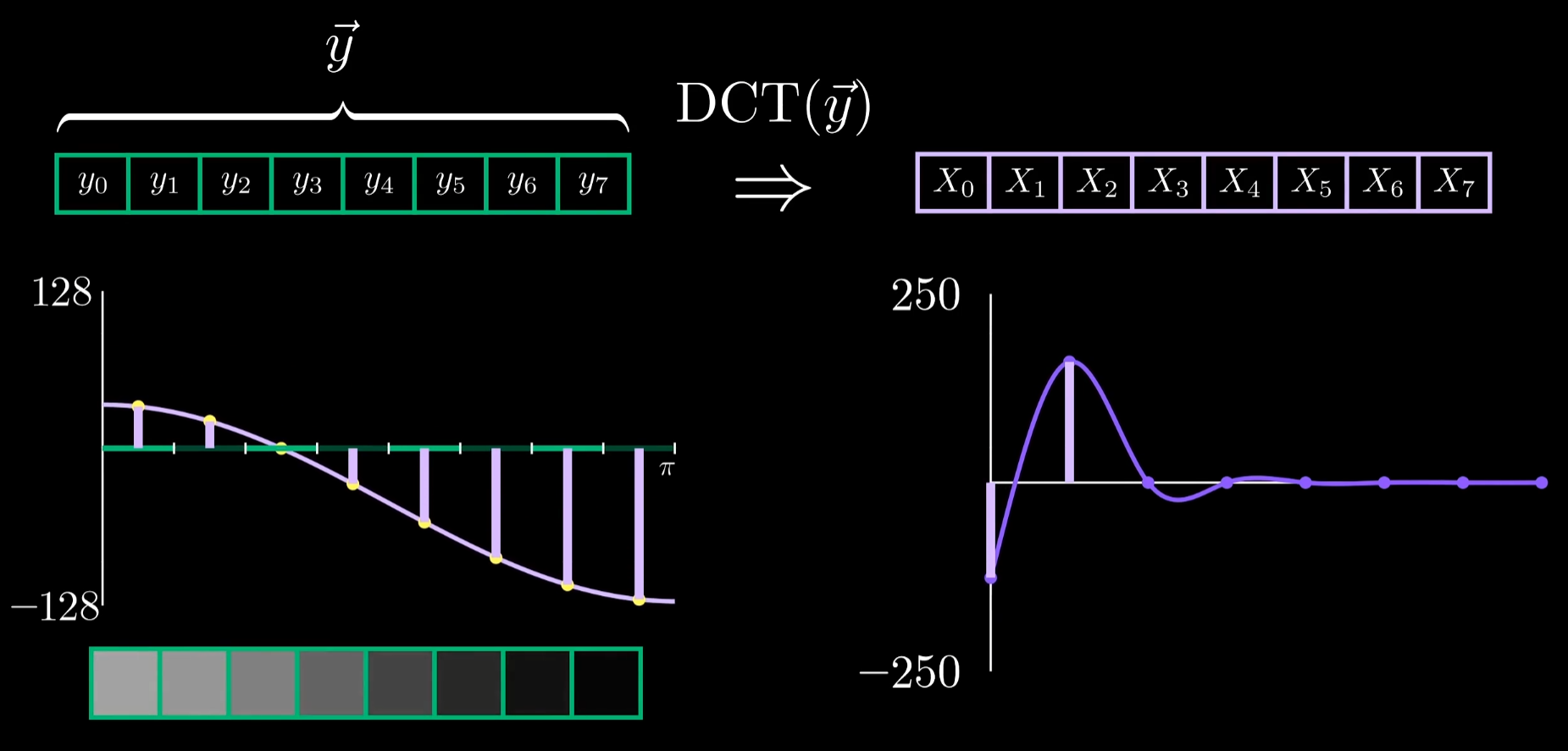
还有什么变动会影响DCT呢?比较简单的是单纯把波整体上下平移,看起来升降信号只影响系数X0。当提高频率时,发现有多个不同的DCT系数与余弦波相对应,当变为cos(2x)后只有系数X2不为0,这个余弦波只是将之前哪个余弦波的频率翻倍了。频率为0的余弦波是一个常值信号提供了标准,去衡量一组像素的整体亮度
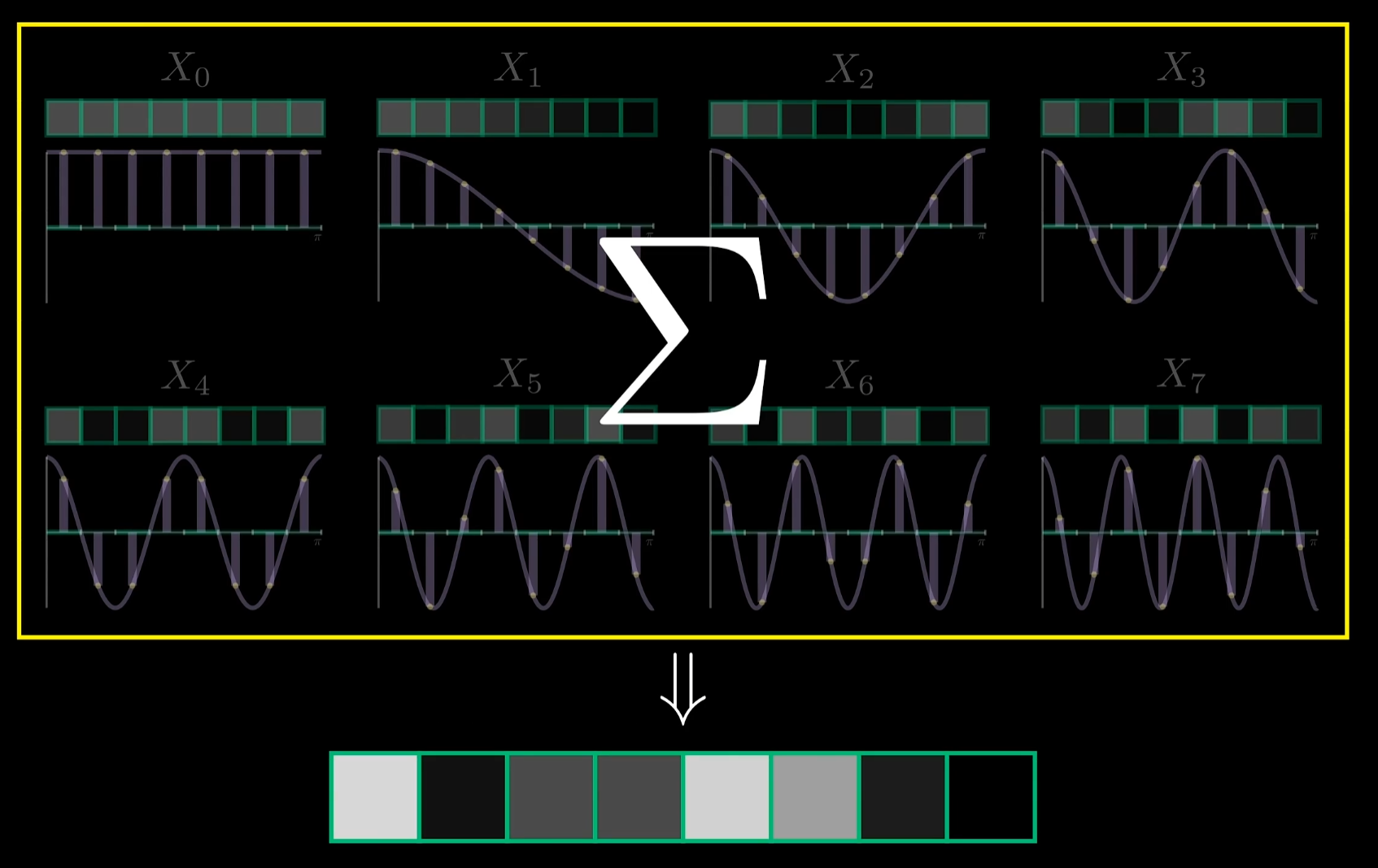
每个频率都对应一个不同的图像模式,DCT的核心是分解出各个基本模式,分析它们对原始图像的贡献,结果发现八个像素的所有可能组合都可表示为这八个余弦波的总和
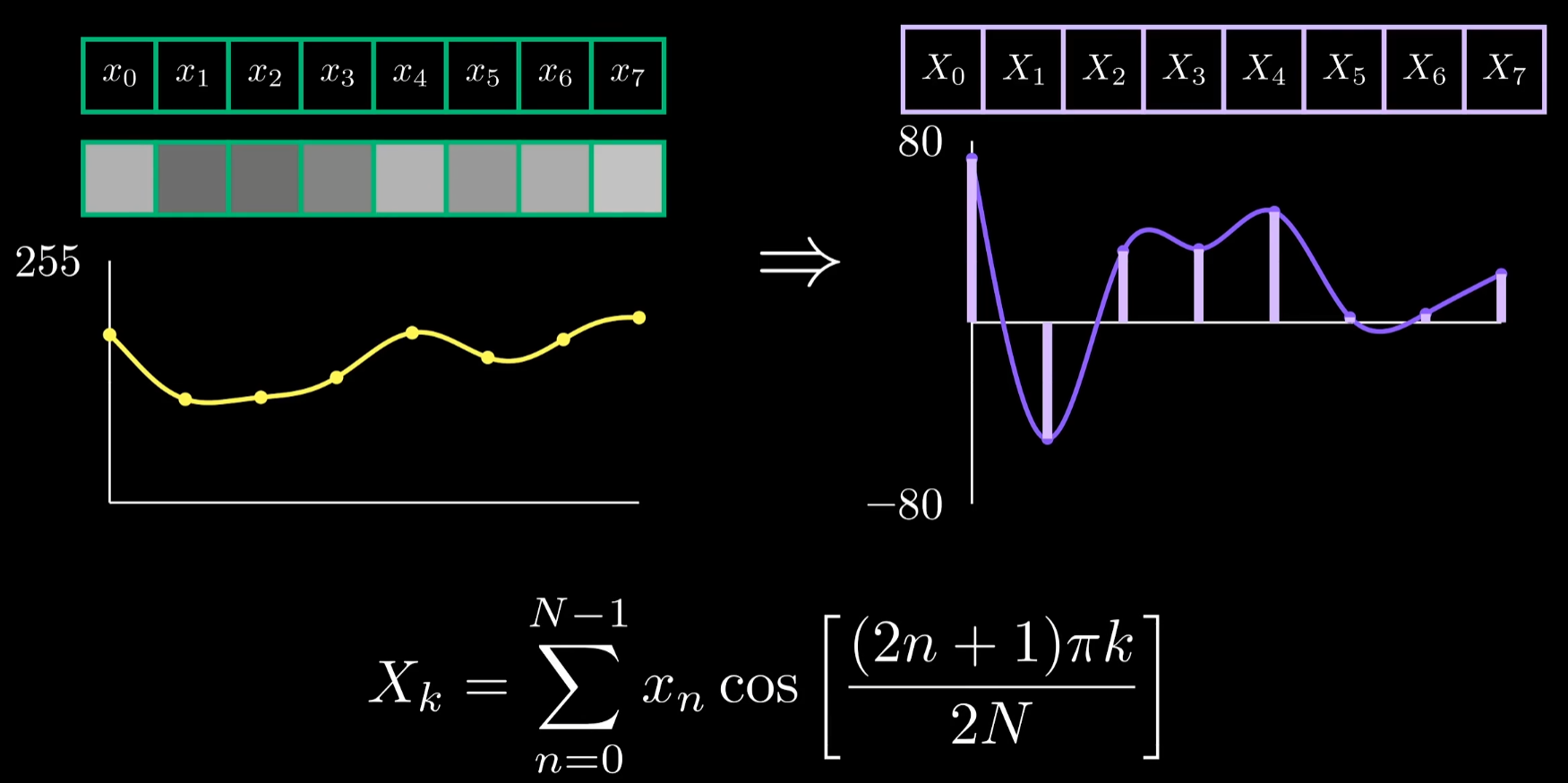
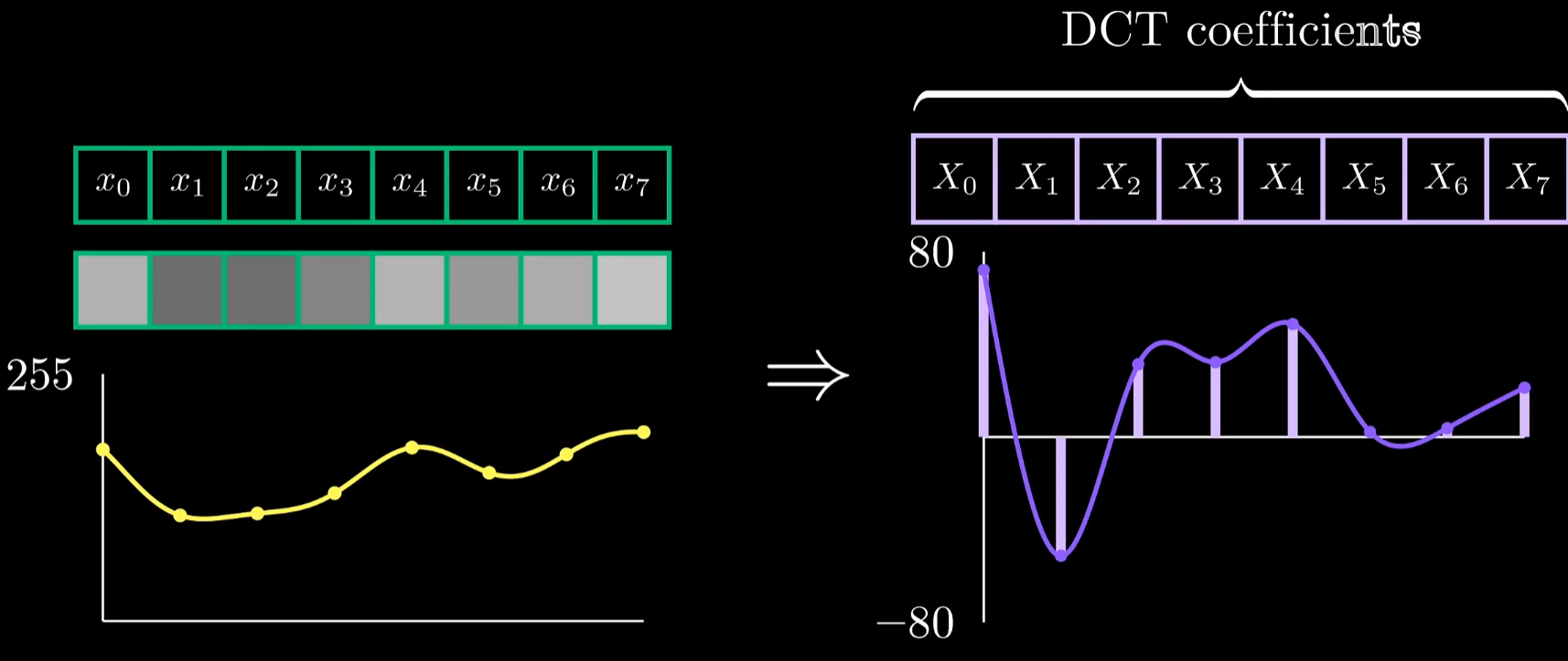
DCT的数学定义如上,其中k为余弦波的频率,原始信号点可以表示为一个矢量,我们可以将余弦波的采样点也改写成矢量
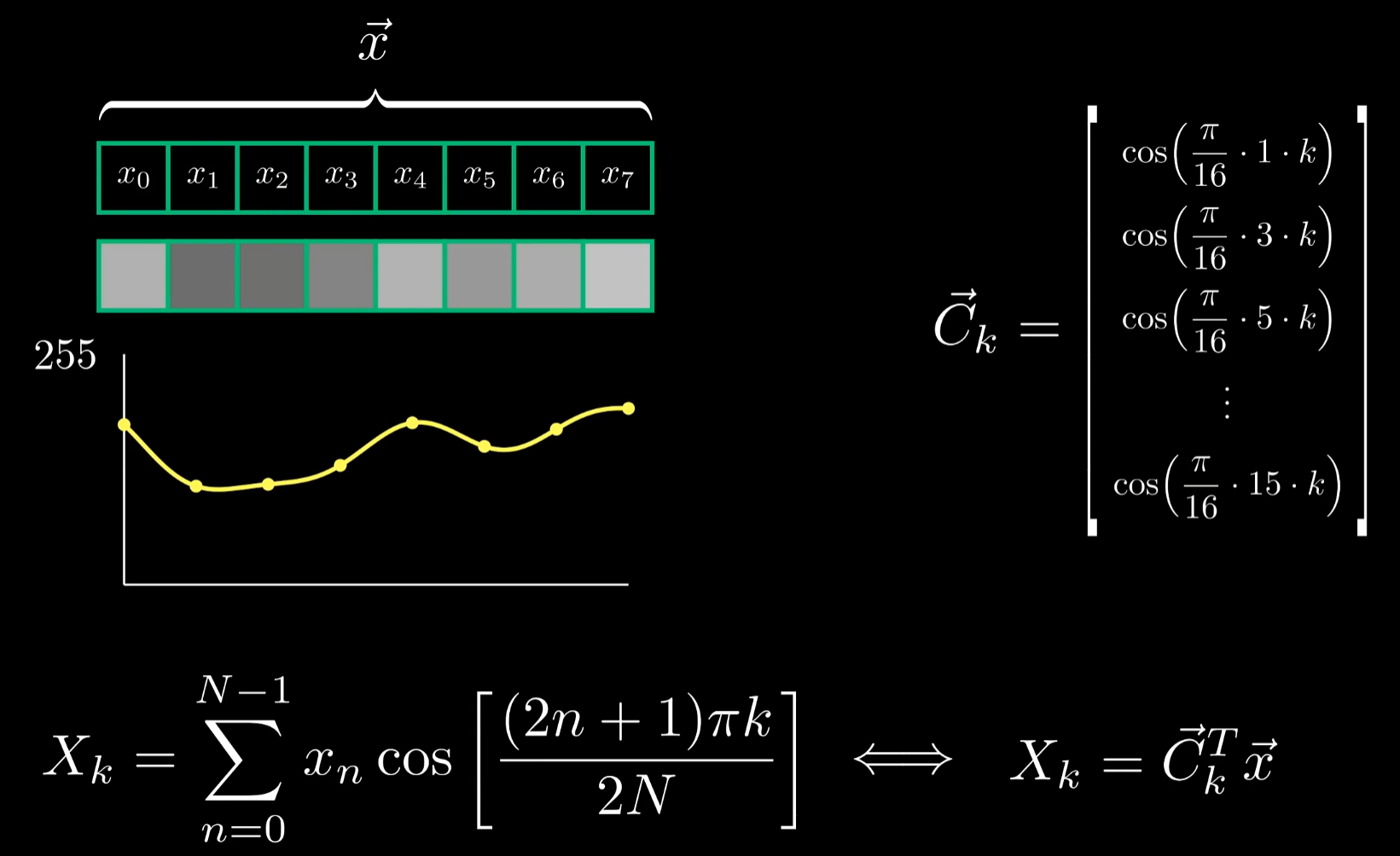
向量点积的形式是衡量两者相似性的好方法,这解释了当我们对频率为k的余弦波采样,将其输入DCT后位于k号位的系数为何会出现尖峰。这两个向量互为倍数,所以点积被最大化了
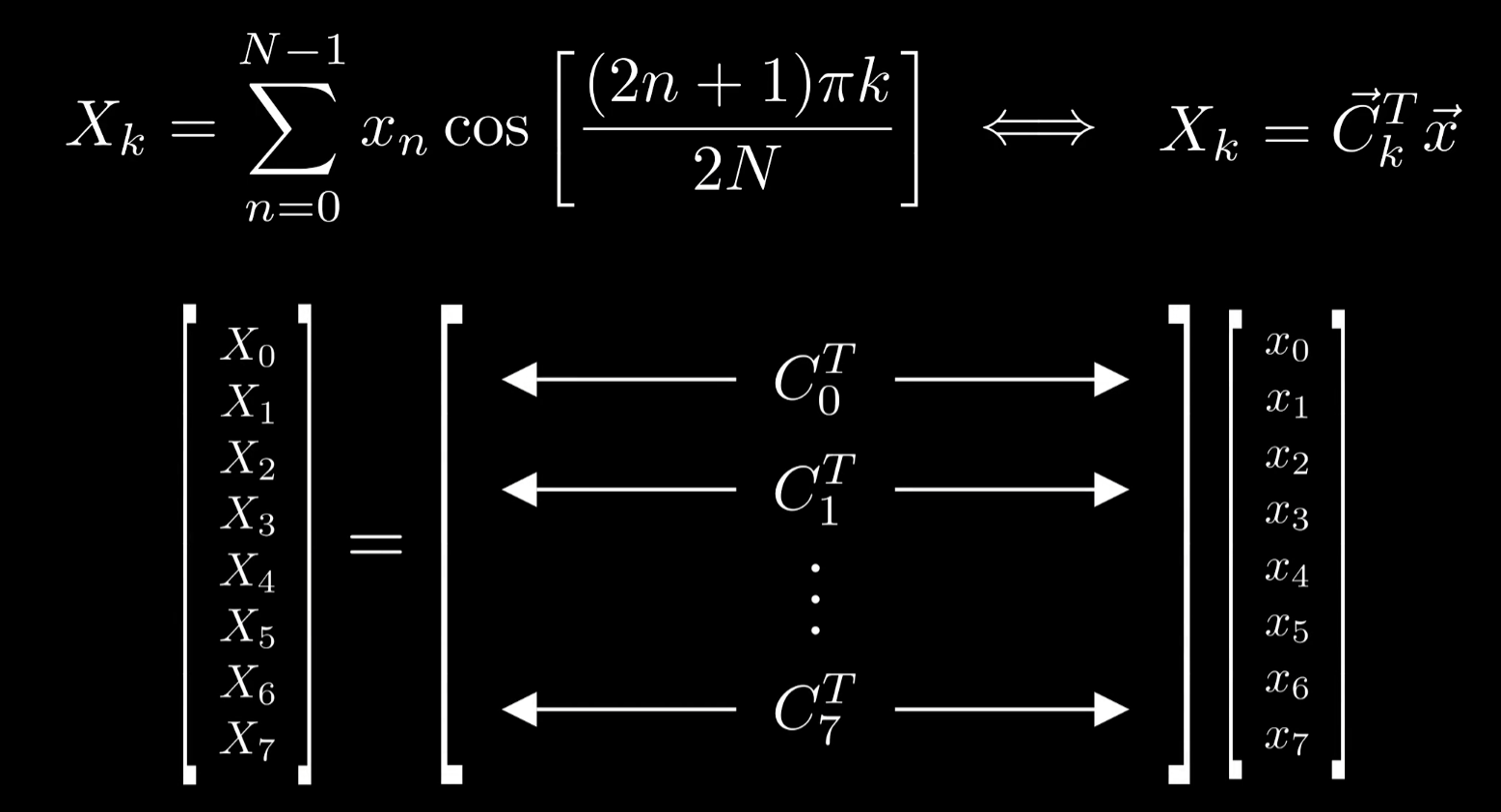
我们可以把整个DCT看成是矩阵与向量之积,矩阵每行是各自频率的余弦波中的采样点,令人震惊的是矩阵中每行都是相互正交的,这就是为什么直接只输入一个特定频率的余弦波时,其他系数没有任何贡献(来自不同余弦波的采样点相互正交 )
扩展:DFT中扩展序列时,是直接采用平移方式引入了不连续的区间,而DCT采用对称形式,消除了这一人为的不连续(扩展后的函数在该点变化非常快,信号分解过程中会出现多个高频信号),而通常高频信号隐藏在这人造的不连续中。这也正是为什么DCT的能量聚集效果会更好。
JPEG如何具体使用DCT

首先将图片分为多个8*8的区域,各个元素减去128使值域中心为0,再对这个矩阵的行列进行DCT变换,各系数分别代表某个8 * 8图案的权重,其他格子都是第一行和第一列这些基础图案的组合
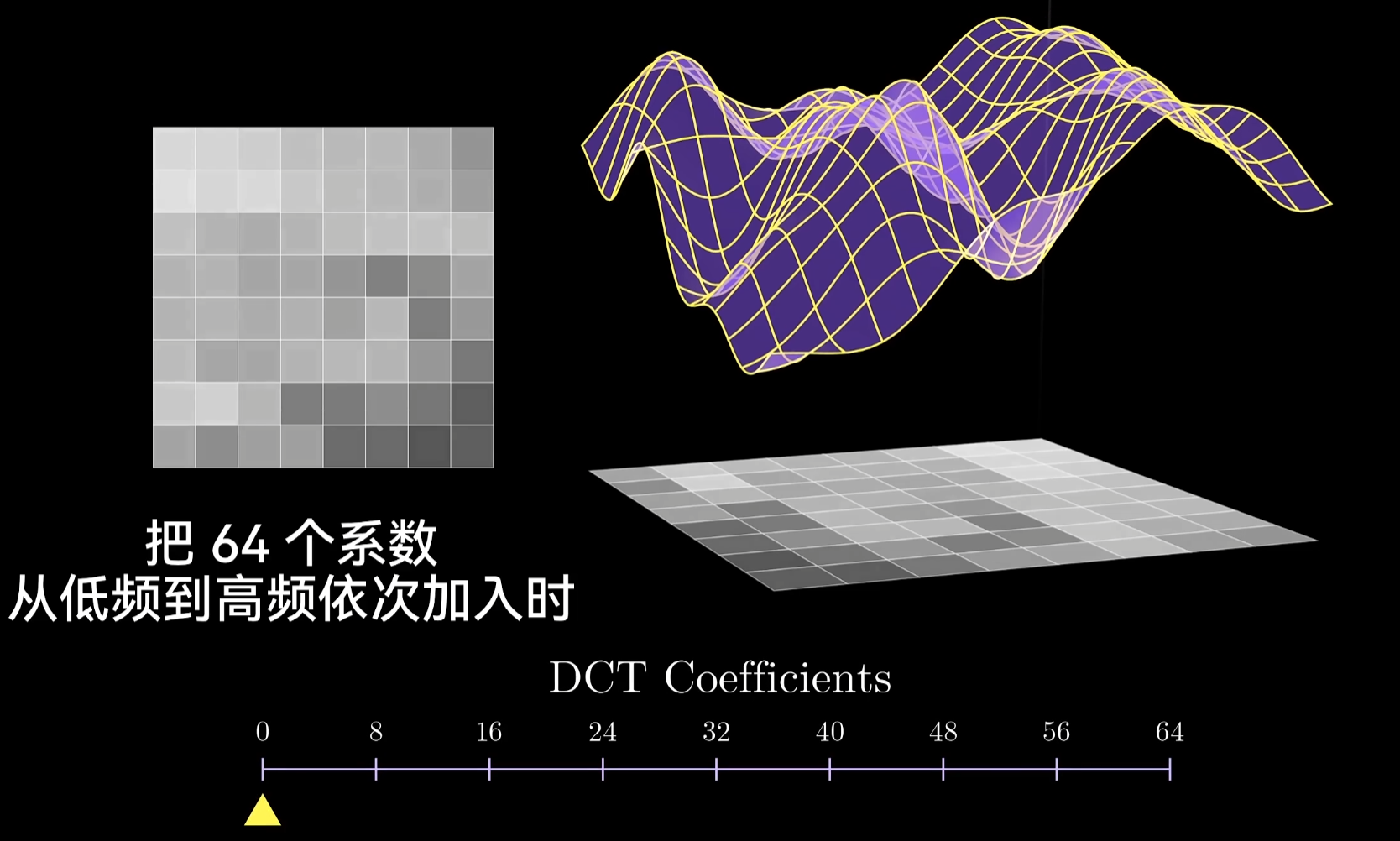
只加入小部分的频率,我们的信号和图像也和原图相差无几了

最大系数在左上角也就是低频部分,有趣的是图里的各个8*8矩阵基本都满足这个性质,这个性质称为能量集中(图像压缩领域的重要概念)。进行变化后,其中最大的那些值会集中在几个低频系数上,复原图像时每个小块只用一部分的系数(最低频的分量)肉眼就很难分辨了,正是这个概念让我们在不降低观感的同时能够高度压缩图片。随着频率的提高,人对高频系数逐渐不敏感,就可以丢弃DCT的高频分量,如何做呢?
DCT如何丢弃高频分量
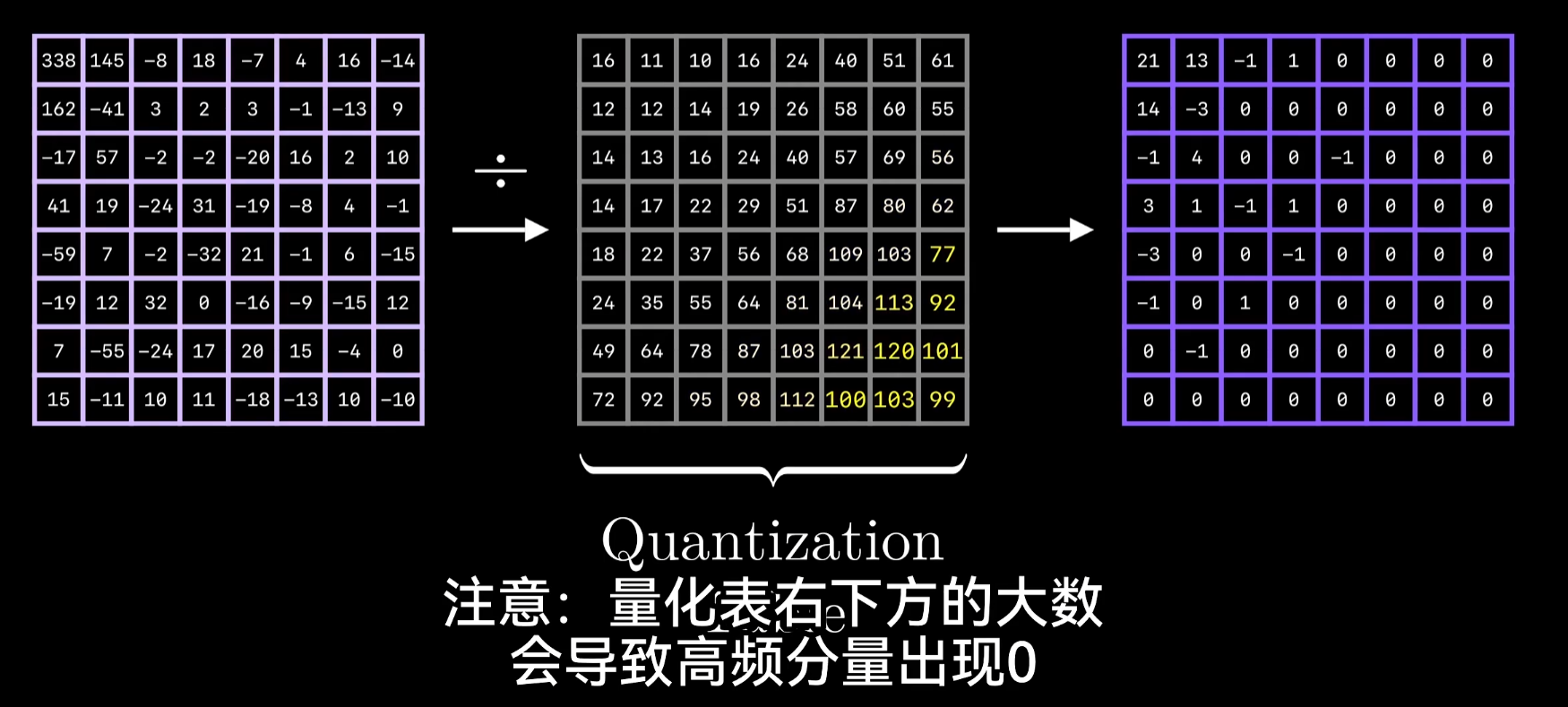
量化: 给定一个8*8矩阵代表DCT输出的频率系数,将每个元素分别除以一个标量值(有不同的量化表分别用于亮度通道和色彩通道),然后取整。
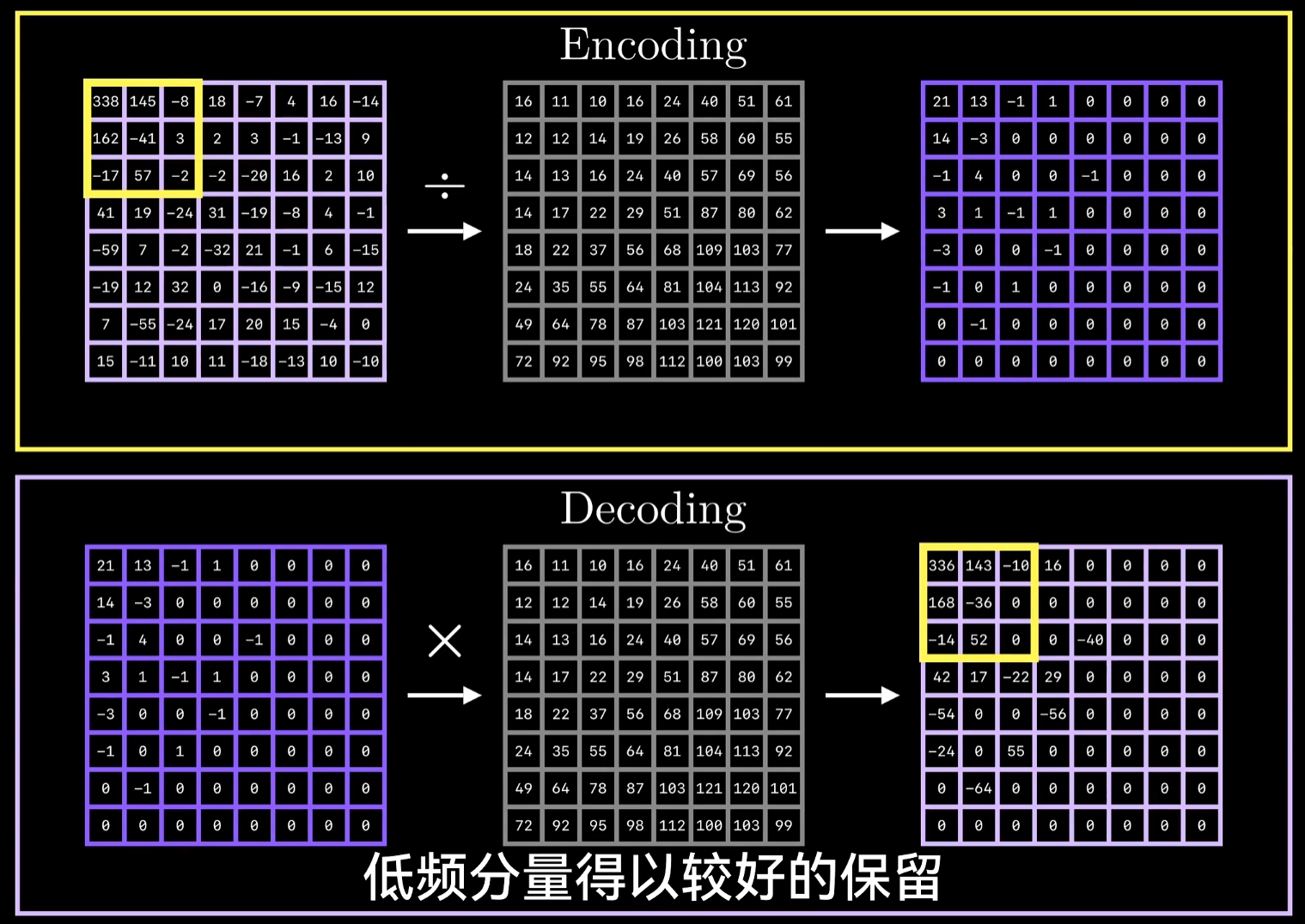
解码阶段不太重要的高频分量会出现一大堆0,完成量化后,可以利用冗余来进一步压缩,这涉及到游程编码和霍夫曼编码的组合。
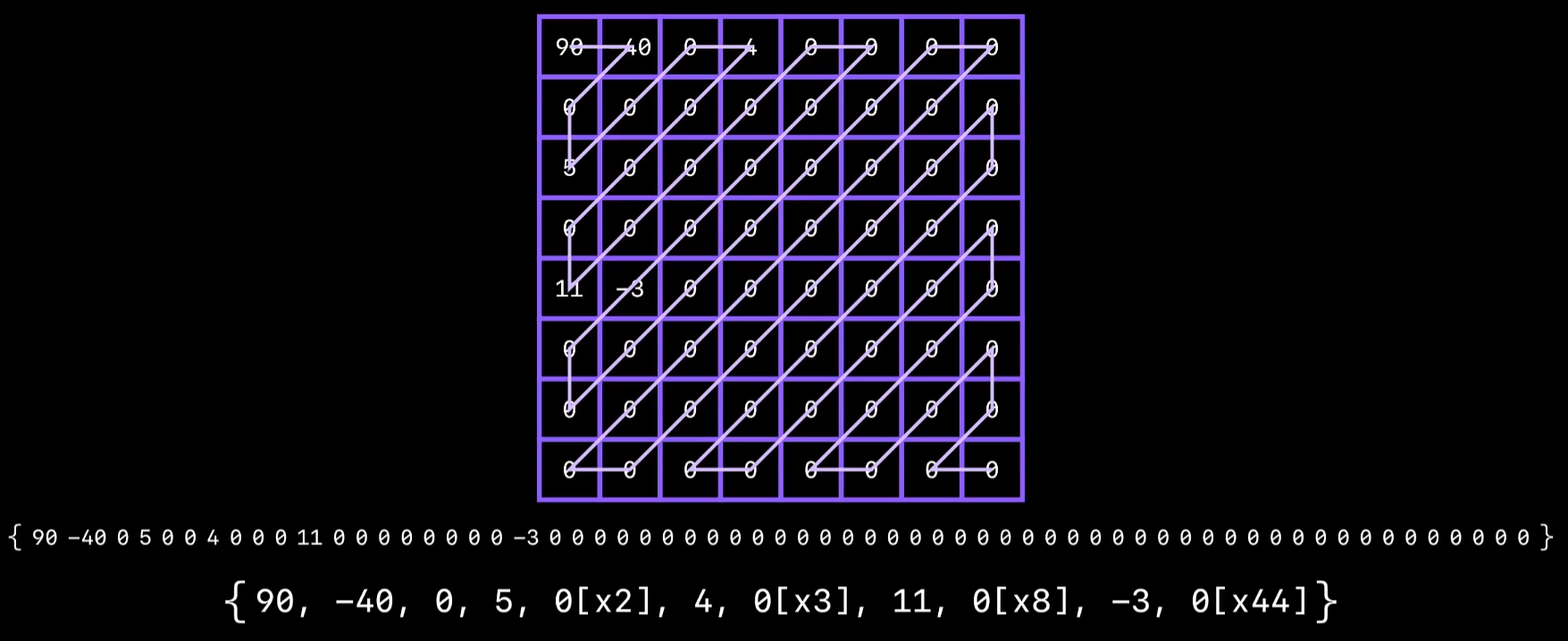
编码将系数按之字形排列,让序列尽量多出现连续0,然后用游程编码压缩,霍夫曼编码较复杂此处省略具体操作。
总结
JPEG中的许多革新时源于人类视觉系统的实验和理解,这让我们知道人眼对色彩和高频信息并不敏感,音频视频压缩上也可同样的技术应用。