Vision GNN: An Image is Worth Graph of Nodes
将图结构应用于图像领域,将VIT中的patches视作nodes。该网络主要由
GCN和FFN组成。其中GCN模块来聚合、处理图结构信息;FFN模块对节点特征作变化,获取节点信息的多样性。论文链接
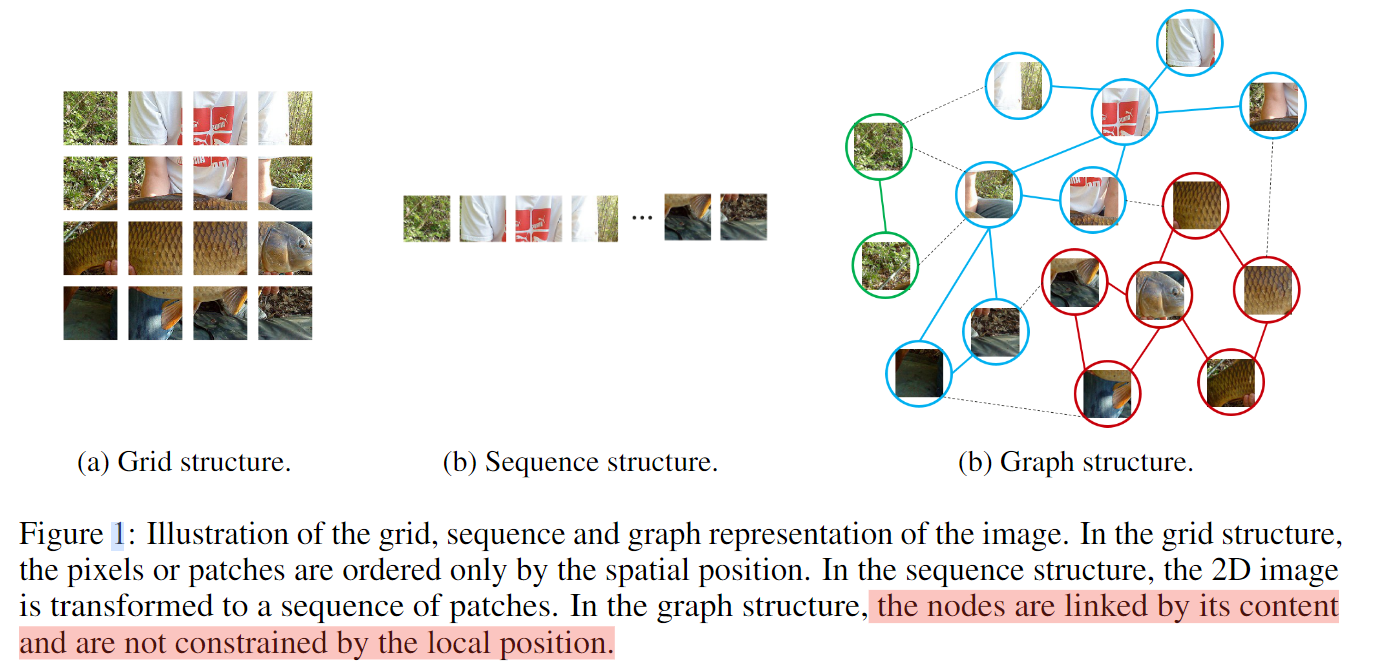
如上图所示,节点之间的连接由其内容确定,不受位置关系限制。网格、序列都可以看成是图的特例。
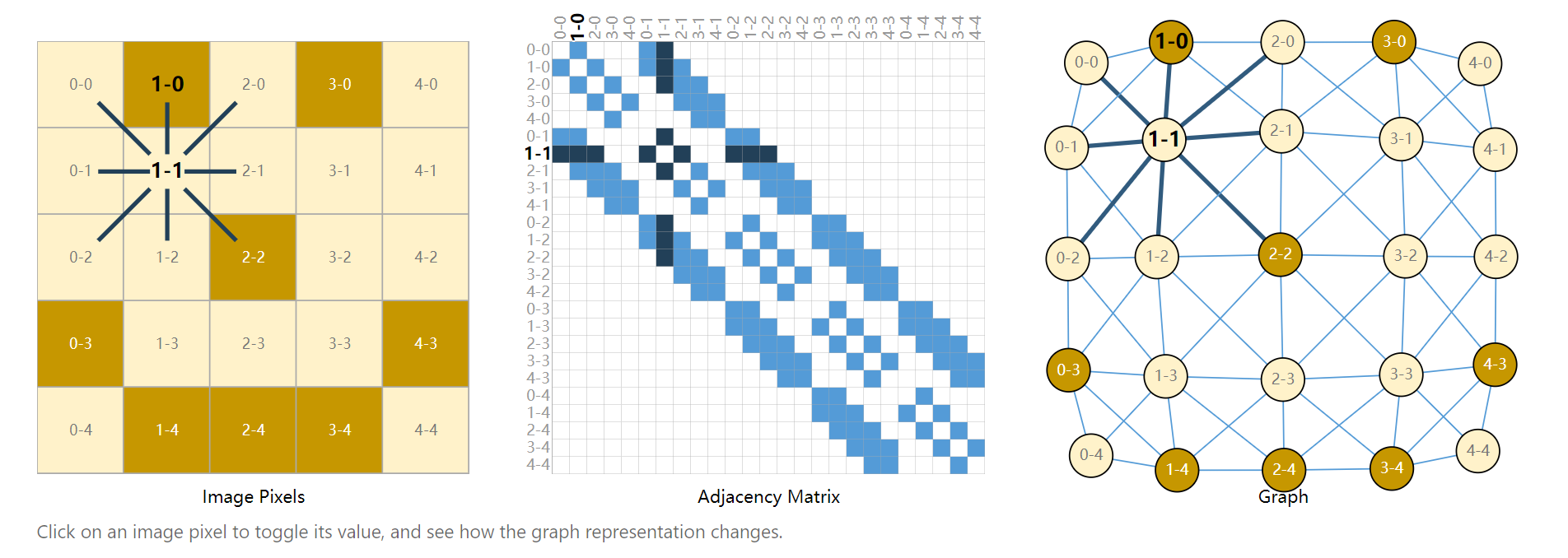
上图是图片如何表示成图的一个例子。蓝色点 表示adjacent matrix,白色点表示无连接;通常是很大的sparse matrix。
How to transform an image to a graph
VIG
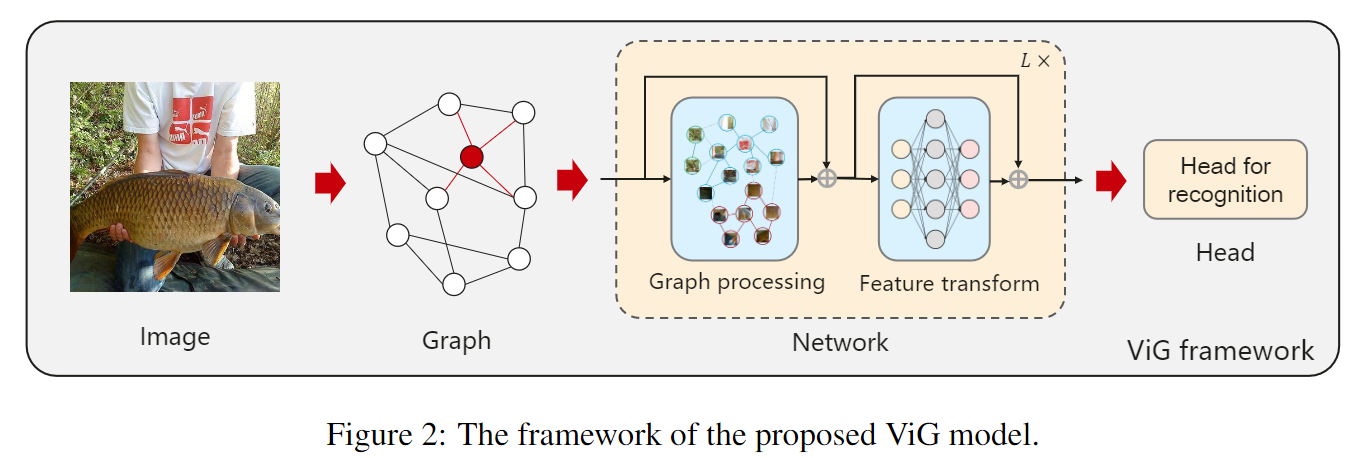
网络的关键在于:如何将图像表示为图结构、如何学习图结构中的视觉表征
Graph Representation of Image

此处K取9~15效果最佳
GCN
图卷积通过聚合相邻节点的特征来实现节点之间的信息交换。

具体的说图卷积分为聚合和更新两个操作。
aggregation operation: 操作通过聚合邻接节点的特征来计算当前节点的表示multi-head update operation: 将聚合后的特征分为h个头,每个头对应不同的更新权重,有利于特征的多样性表达。

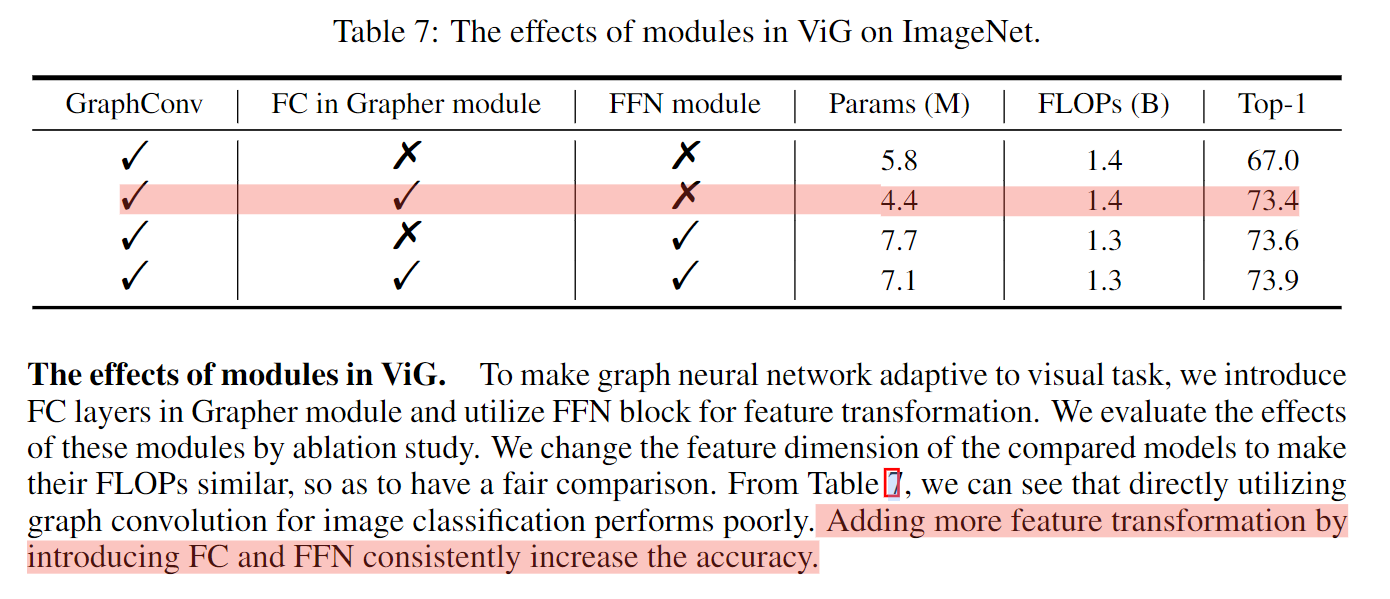
GCN在网络变深后会有过平滑现象,这会降低节点特征的区分度,导致视觉识别性能下降。本文在图卷积后的每个节点内引入了更多的特征变化,促增加节点特征多样性。

本文对应的解决策略如公式6所示。为了进一步提高特征转换能力和缓解过平滑现象,本文在每个节点上使用FFN,过程如下所示。
基于本节的graph representation of images 和ViG block,VIG网络可以随着网络的加深,保持特征的多样性,从而学习判别性的表示。
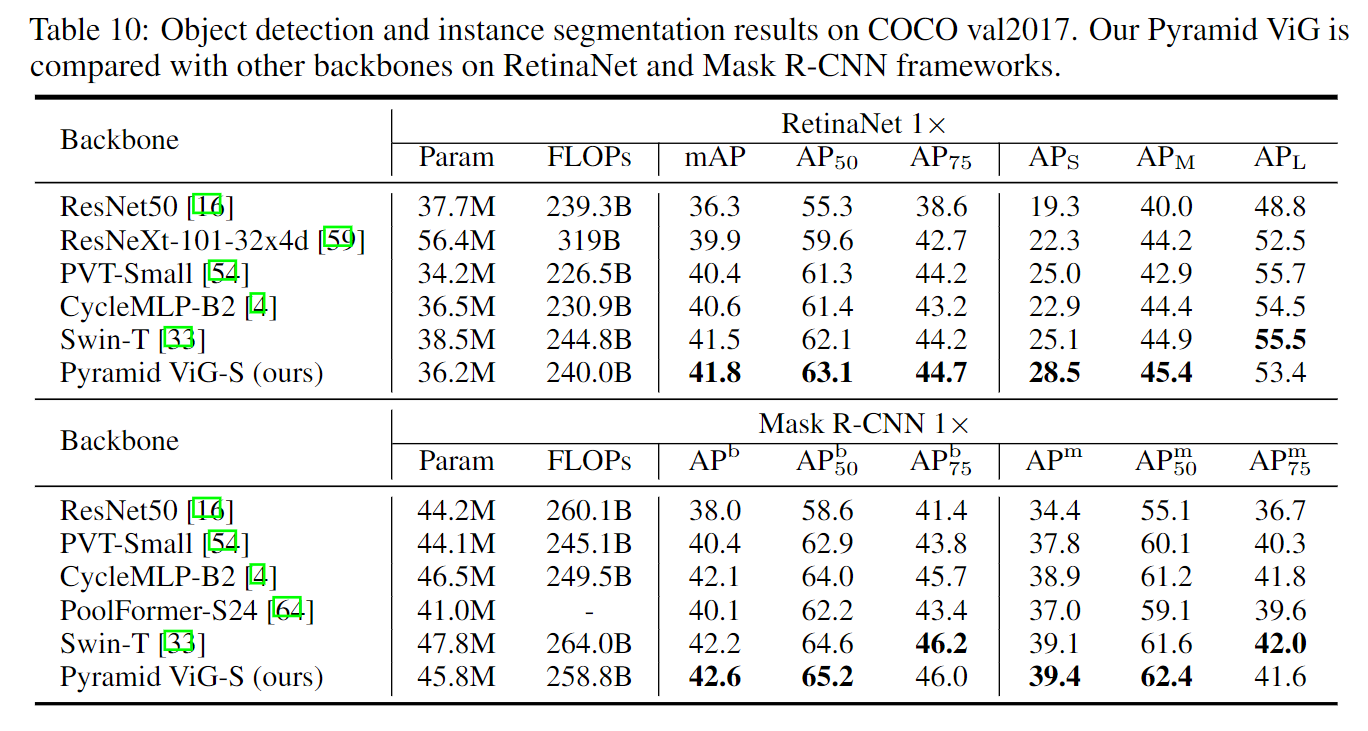
Experiments
Visualization

可视化结果:浅层邻接节点的选取基于低级、局部特征如:颜色和纹理,深层中邻接节点的选取更依赖于语义等高级特征。
Pseudocode


