mmcv功能概览
-
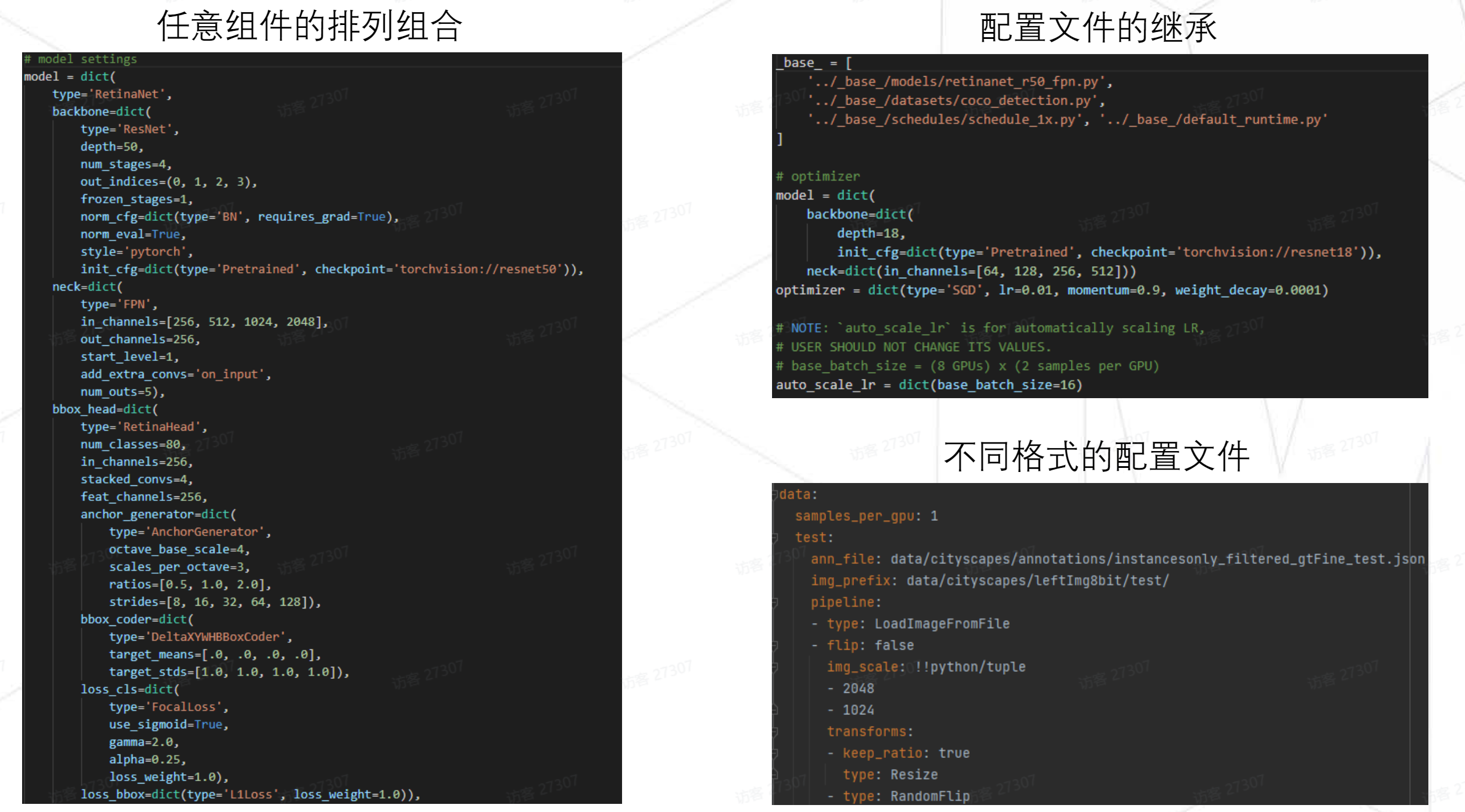
配置文件的可读性比原始的好,直接反映了配置和实现的关系。上图左中
type表示此模型为RetinaNet,后续字典都是其属性。 -
配置文件通过继承更清晰其中变动之处,不用每次去找不同之处了。
-
不仅支持
python格式的配置文件,也支持yaml等格式,但灵活性没那么好。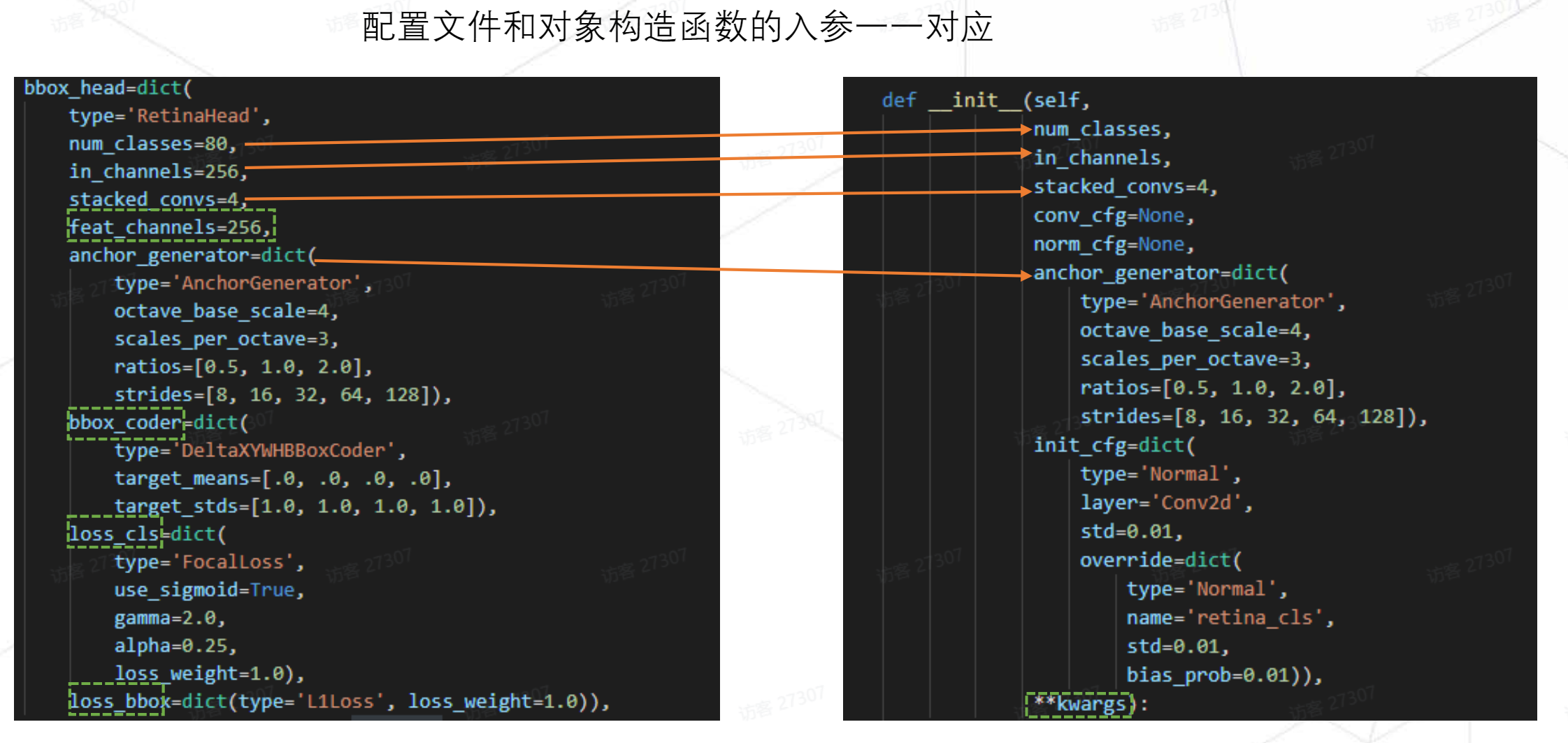
配置文件中的各种参数代表了RetinaHead在构造时对应的值。其中绿色虚线框对应**kwargs,这些属性并不是给RetinaHead使用的,而是给其父类的。我们在RetinaHead中会调用父类的方法,利用**kwargs将父类对应的属性初始化
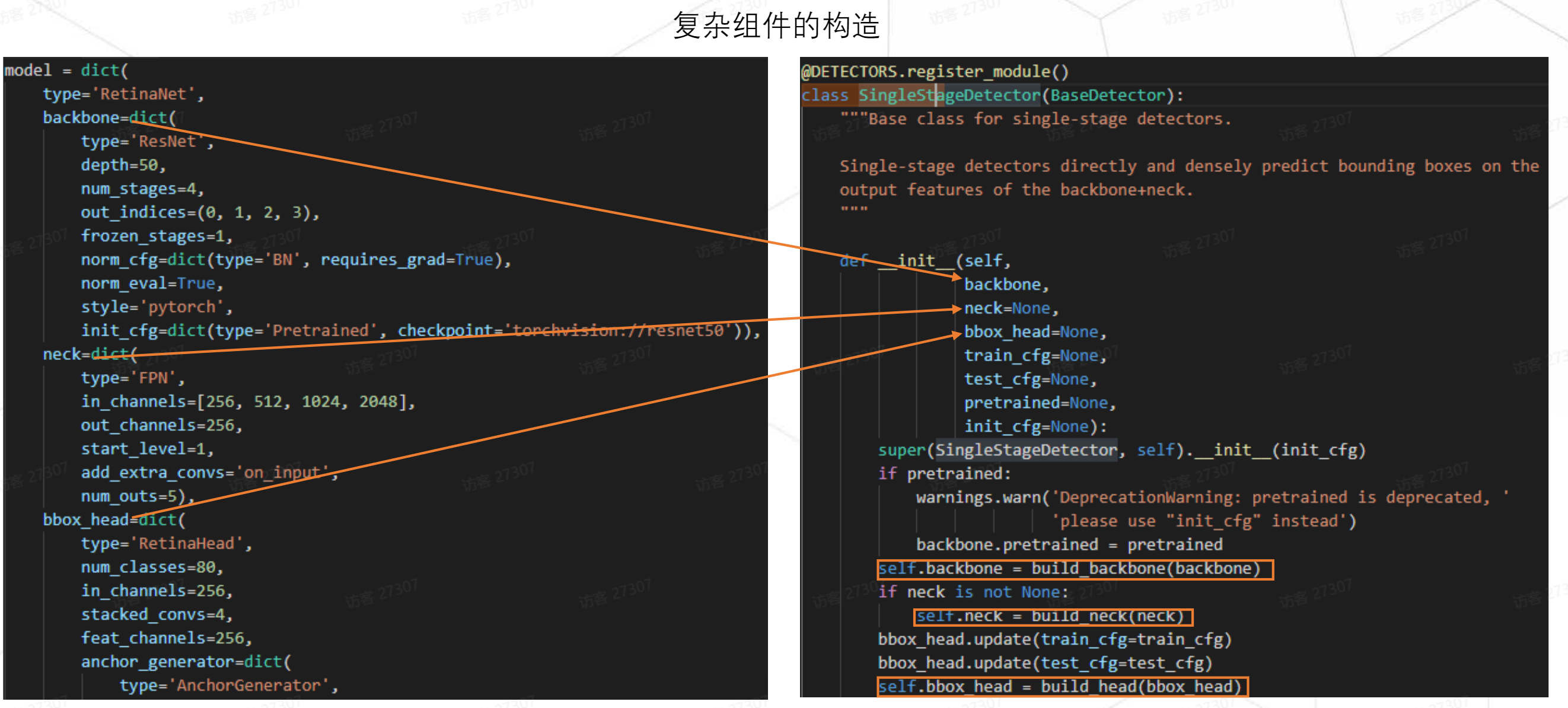
RetinaHead仅仅只是RetinaNet中的一个字段,即传入的最外层传入一个type内层都是带type结构的子结构字典。我们只要保证在具体类的实现中,内部有去解析这些字典。对应图中RetinaNet 父类SingleStangeDetector中通过build_backbone在内部完成了对应属性的实例化
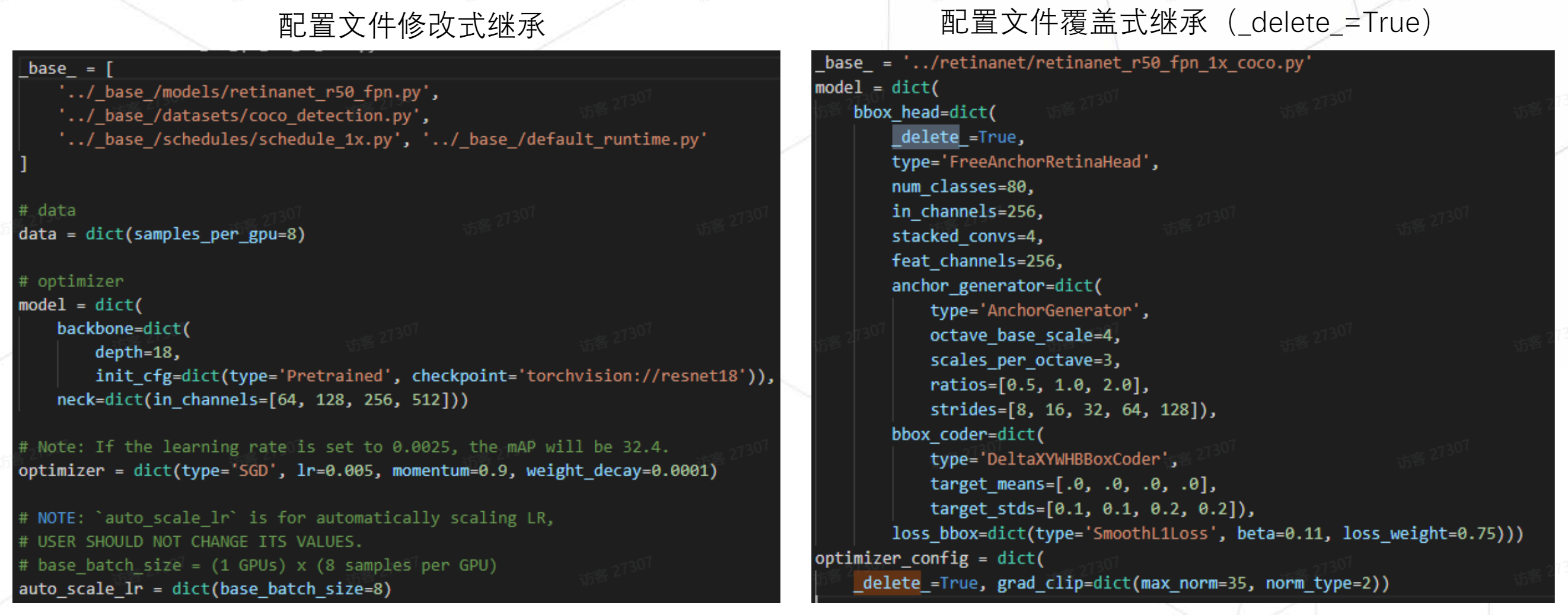
_base_申明一个配置文件列表,会将所有配置文件中定义的变量加载进来。其中model是对父类中内部字段进行修改而不是覆盖。
只有在其中加入_delete_属性才会覆盖父类中对应字段
配置文件通过一个列表来表示,但不能显示的知道配置文件中到底由哪些组件构成。vscode插件Config View可以解决这个问题
Config与Registry
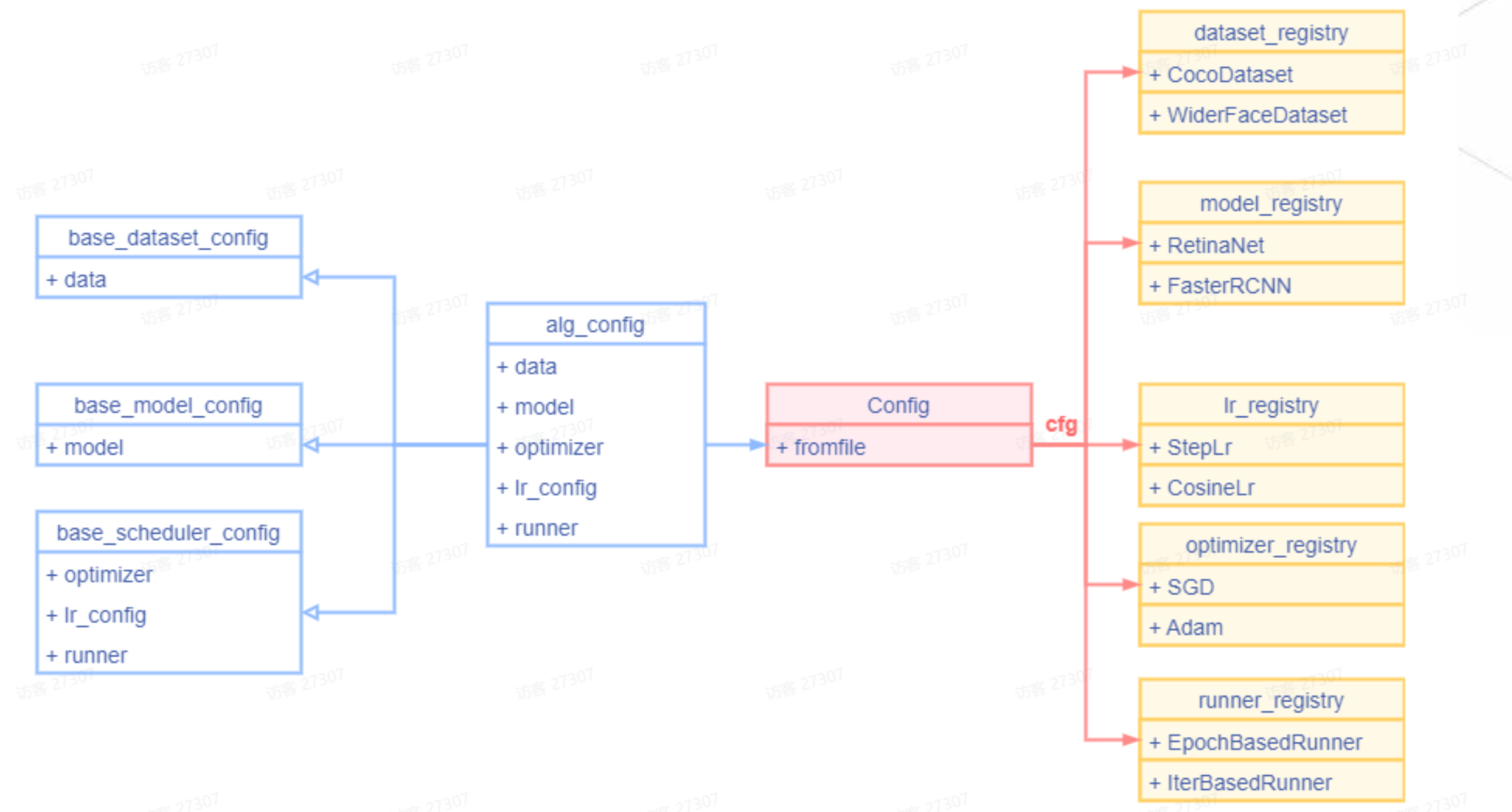
从Config中取对应字段的配置信息还没有将其变成具体的实例只有解析功能,要通过Registry将对应实例构建出来。
根据type字段将cfg粗略分为两个类型。type类型:训练时该变量的实例化后类型,其余字段为该变量实例化所需的参数。Registry 会根据type 和其他参数将变量实例化。
mmcv训练最外层的抽象是runner,其有非常多的属性,如果在配置文件中写入runner,会导致嵌入很多层级的字典,阅读不便。所以在可读性和一一映射关系上做了取舍。对于dataloader和dataset为了防止文件嵌套层级过深,只将一些显而易见的属性写在最外层,不将这些暴露给用户 。

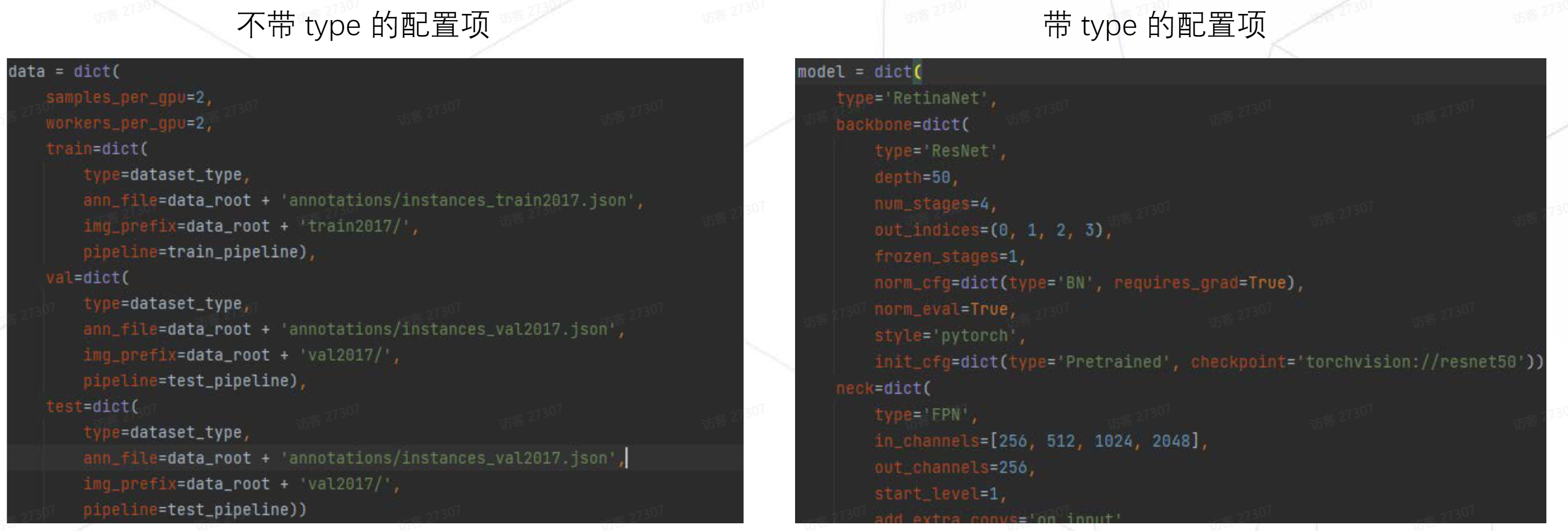
-
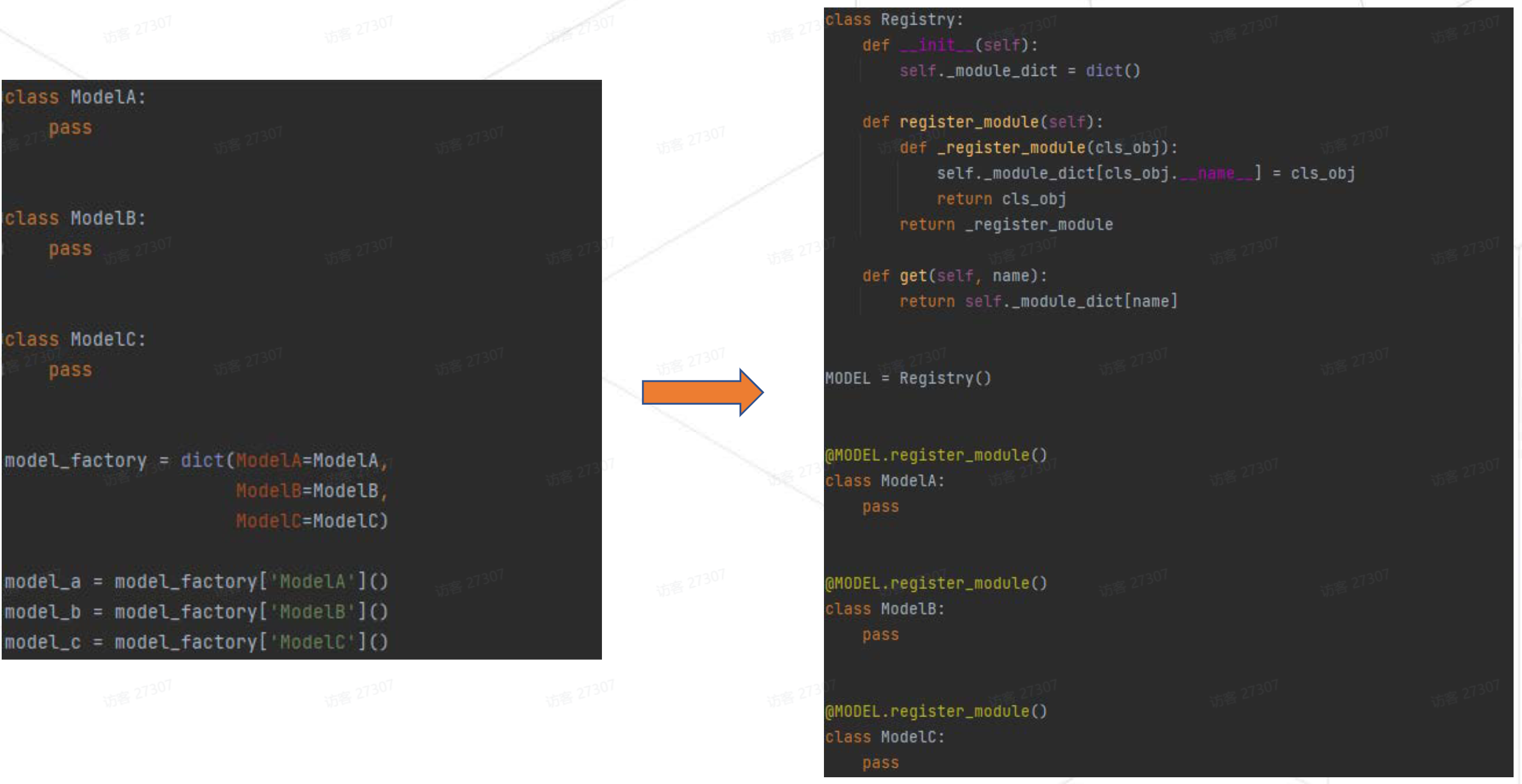
左侧的方式每次构建完模型后都要手动向
model_factory中加入一个字段。 -
右侧是个
Registry的最简形式。每个Registry实例都会有一个module_dict字典,利用一个装饰器实现将字符串与模型类的映射会自动添加到module_dict中,多一个模型只需多一行注册,便于维护。 -
注册功能的具体用法:一种是装饰器的写法,只要对应脚本被执行(本身在运行该脚本或者在运行其他脚本时
import该脚本,触发任意一种就完成注册行为)一种是注册外部模块的写法,将其作为函数使用。

register_module方法中可以传参,意味着不仅可以注册自己写的模块还可以注册外部的模块。
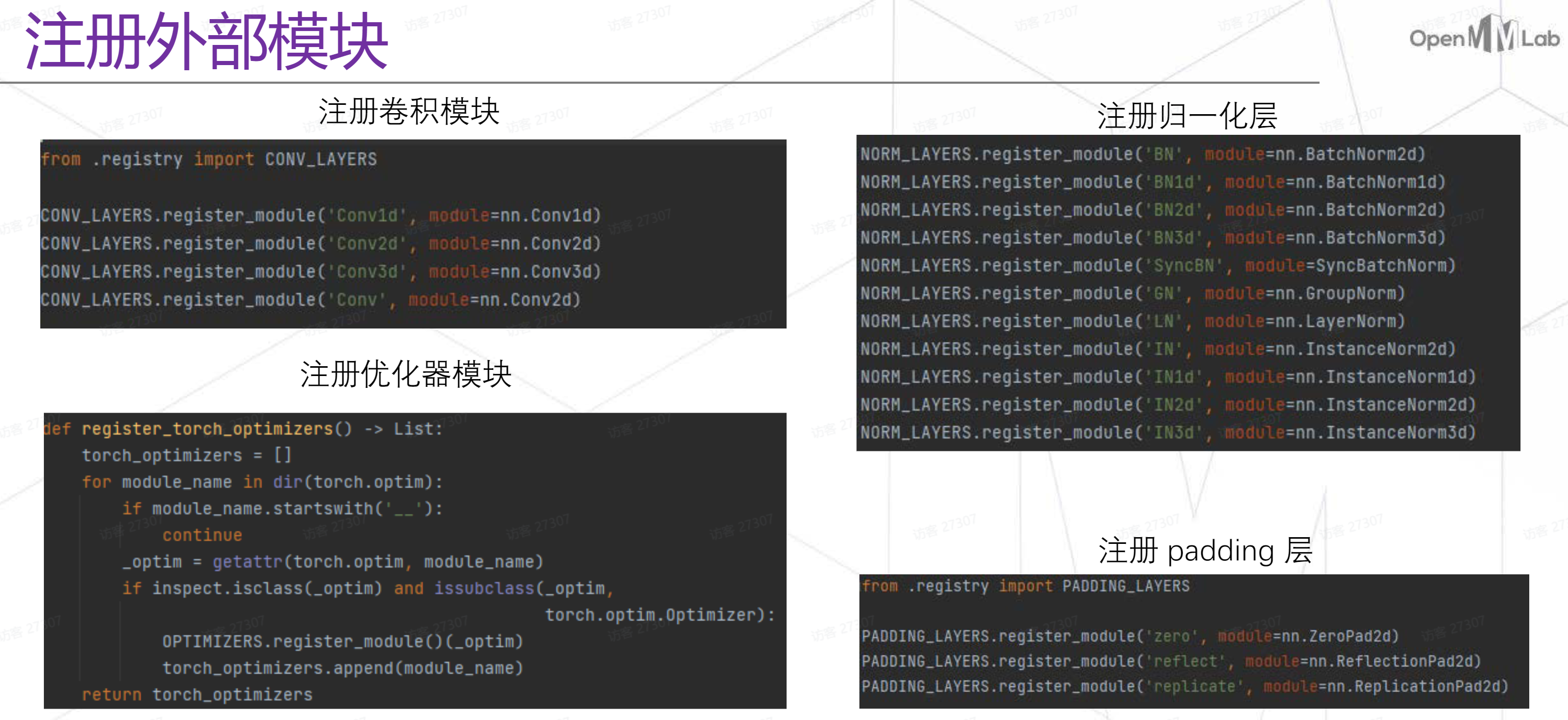
正因为registry可以注册外部模块我们才能在配置文件中调用到这些模块。
以上注册代码都写在某个模块中 ,要注册这些模块必须要运行对应脚本。
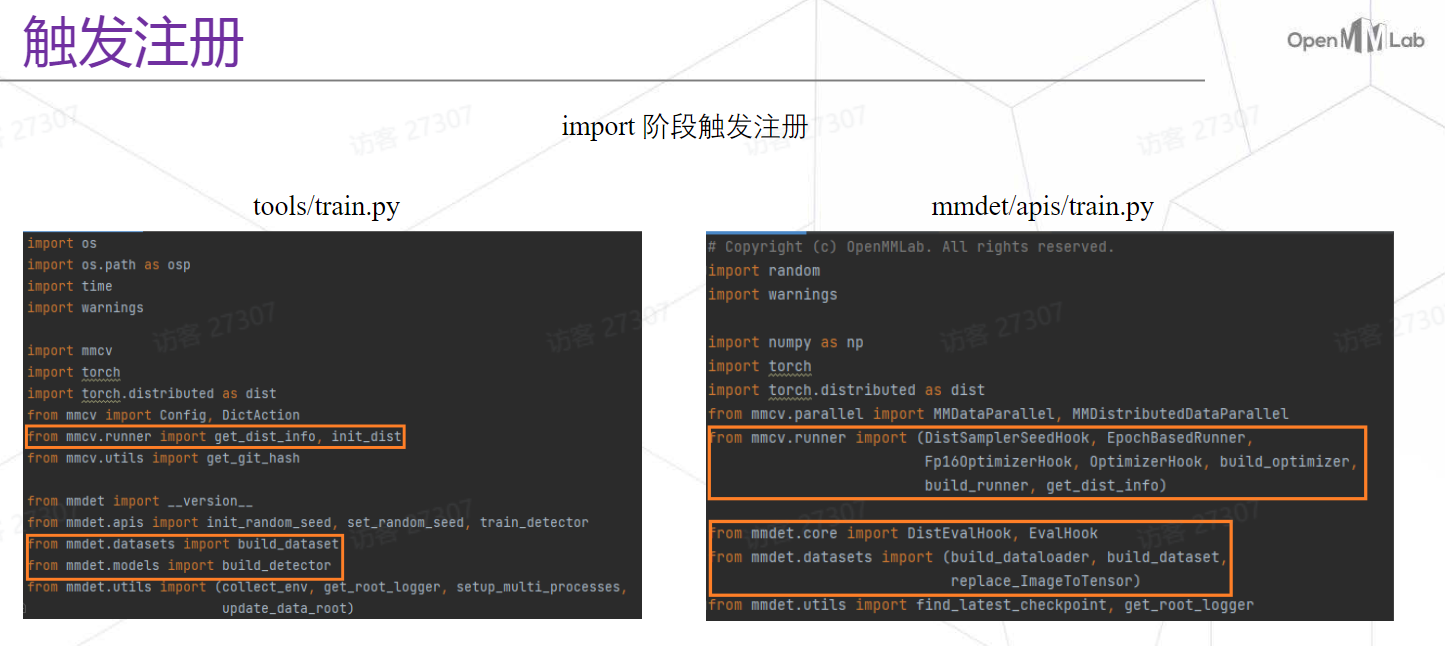

测试代码的注册过程在脚本执行过程就完成了注册,训练中注册过程可通过import。
侵入式注册:这种链式的行为导致mmdet更新后可能会与本地分支产生冲突。非侵入式注册则的方式则不需要修改对应的算法库。
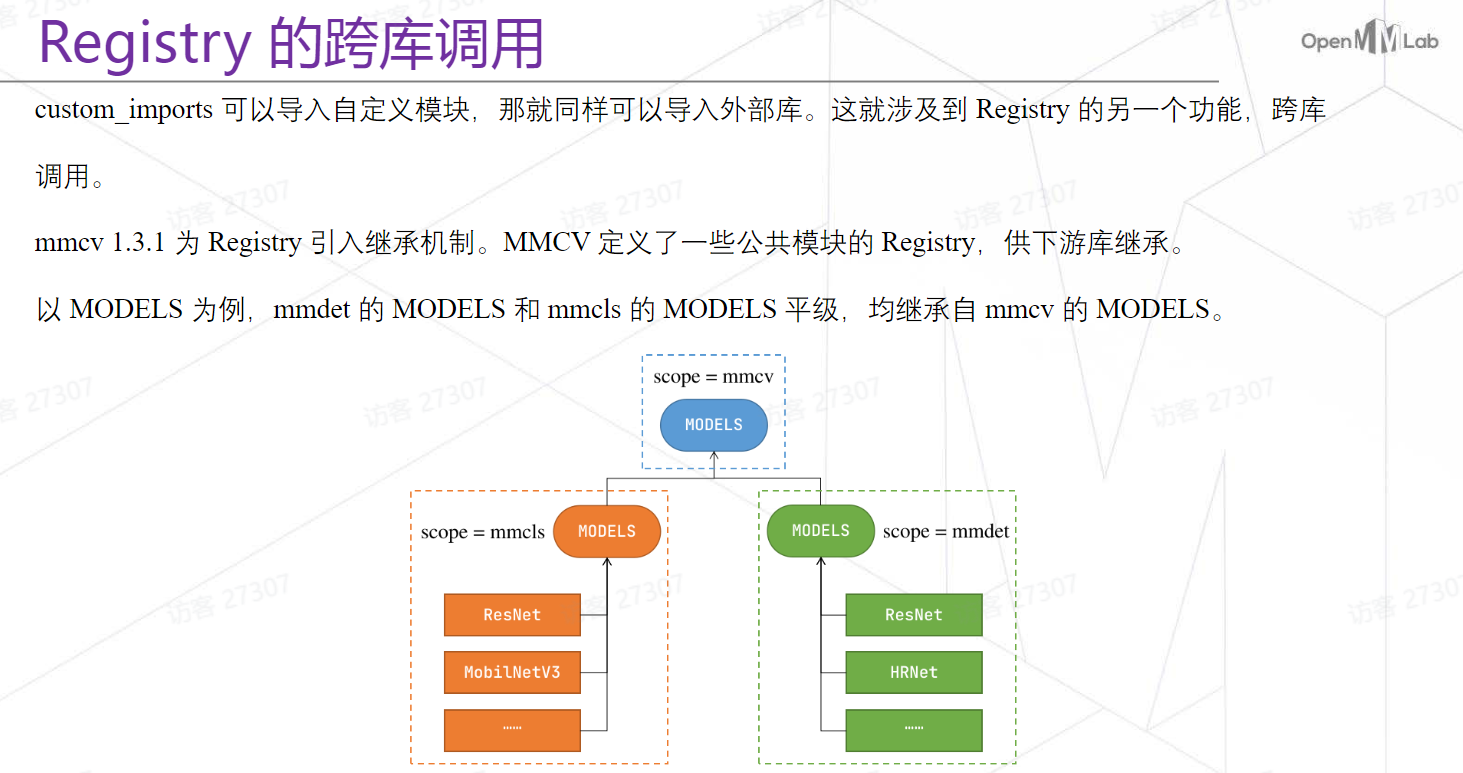
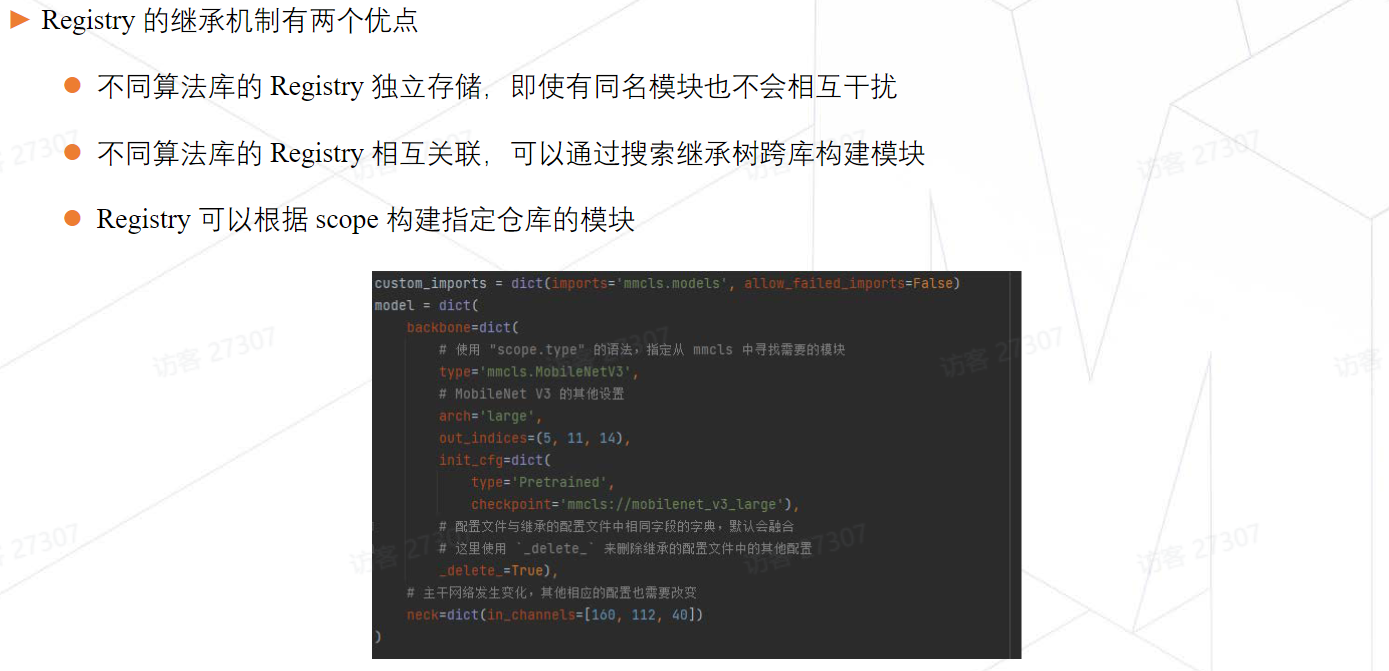

MMCV的Hook
Hook
如果应用程序或者模块组件有固定的执行流程,且有扩展需求,可以通过钩子编程的方式来非侵入式的扩展功能。
以一个简单的神经网络为例:
1 | import torch |
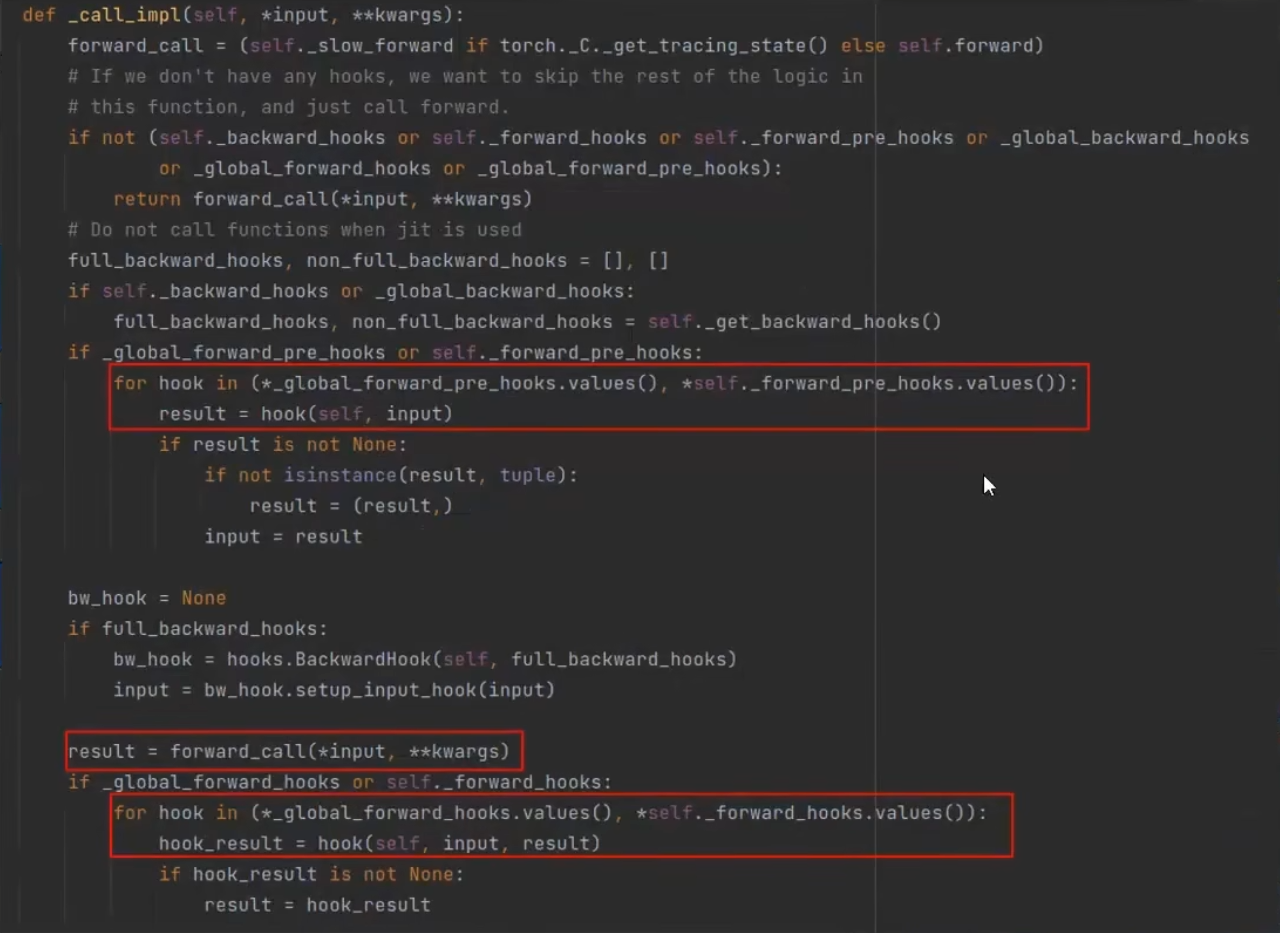
在调用nn.Module的forward_call方法前、后会调用注册好的hook方法。