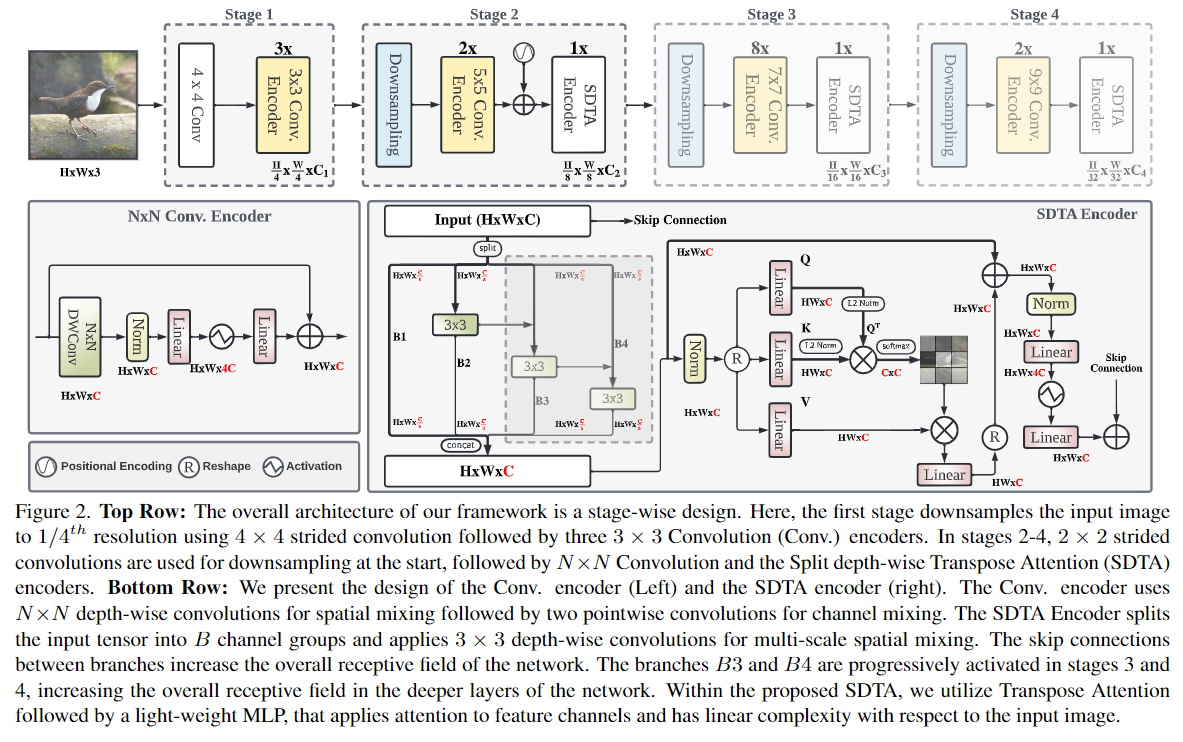
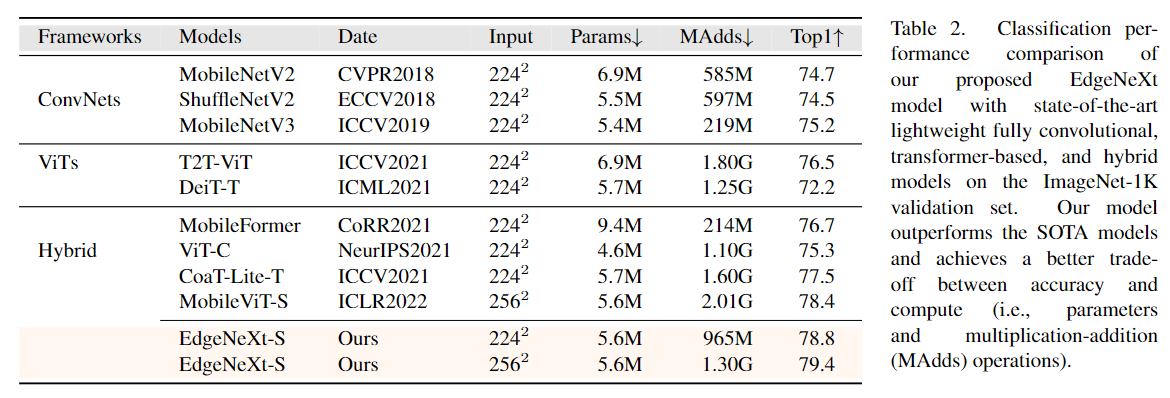
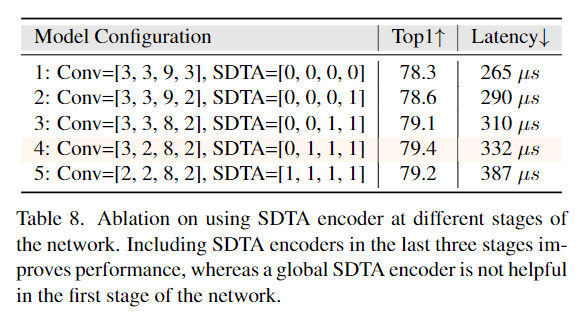
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
| class SDTAEncoder(nn.Module):
def __init__(self, dim, drop_path=0., layer_scale_init_value=1e-6, expan_ratio=4,
use_pos_emb=True, num_heads=8, qkv_bias=True, attn_drop=0., drop=0., scales=1):
super().__init__()
width = max(int(math.ceil(dim / scales)), int(math.floor(dim // scales)))
self.width = width
if scales == 1:
self.nums = 1
else:
self.nums = scales - 1
convs = []
for i in range(self.nums):
convs.append(nn.Conv2d(width, width, kernel_size=3, padding=1, groups=width))
self.convs = nn.ModuleList(convs)
self.pos_embd = None
if use_pos_emb:
self.pos_embd = PositionalEncodingFourier(dim=dim)
self.norm_xca = LayerNorm(dim, eps=1e-6)
self.gamma_xca = nn.Parameter(layer_scale_init_value * torch.ones(dim),
requires_grad=True) if layer_scale_init_value > 0 else None
self.xca = XCA(dim, num_heads=num_heads, qkv_bias=qkv_bias, attn_drop=attn_drop, proj_drop=drop)
self.norm = LayerNorm(dim, eps=1e-6)
self.pwconv1 = nn.Linear(dim, expan_ratio * dim)
self.act = nn.GELU()
self.pwconv2 = nn.Linear(expan_ratio * dim, dim)
self.gamma = nn.Parameter(layer_scale_init_value * torch.ones((dim)),
requires_grad=True) if layer_scale_init_value > 0 else None
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x):
input = x
spx = torch.split(x, self.width, 1)
for i in range(self.nums):
if i == 0:
sp = spx[i]
else:
sp = sp + spx[i]
sp = self.convs[i](sp)
if i == 0:
out = sp
else:
out = torch.cat((out, sp), 1)
x = torch.cat((out, spx[self.nums]), 1)
B, C, H, W = x.shape
x = x.reshape(B, C, H * W).permute(0, 2, 1)
if self.pos_embd:
pos_encoding = self.pos_embd(B, H, W).reshape(B, -1, x.shape[1]).permute(0, 2, 1)
x = x + pos_encoding
x = x + self.drop_path(self.gamma_xca * self.xca(self.norm_xca(x)))
x = x.reshape(B, H, W, C)
x = self.norm(x)
x = self.pwconv1(x)
x = self.act(x)
x = self.pwconv2(x)
if self.gamma is not None:
x = self.gamma * x
x = x.permute(0, 3, 1, 2)
x = input + self.drop_path(x)
return x
class XCA(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
self.temperature = nn.Parameter(torch.ones(num_heads, 1, 1))
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads)
qkv = qkv.permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2]
q = q.transpose(-2, -1)
k = k.transpose(-2, -1)
v = v.transpose(-2, -1)
q = torch.nn.functional.normalize(q, dim=-1)
k = torch.nn.functional.normalize(k, dim=-1)
attn = (q @ k.transpose(-2, -1)) * self.temperature
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).permute(0, 3, 1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
@torch.jit.ignore
def no_weight_decay(self):
return {'temperature'}
|