End-to-End Object Detection with Transformers
第一个端到端的检测器,没有了anchor和nms后处理,简化了流程。不过训练时间长,小物体检测效果差。DETR的成功主要还是Transformer的成功,之前也试过基于集合的目标函数、Encoder-Decoder的架构效果都不好,主要原因是特征不够好。

主要贡献:
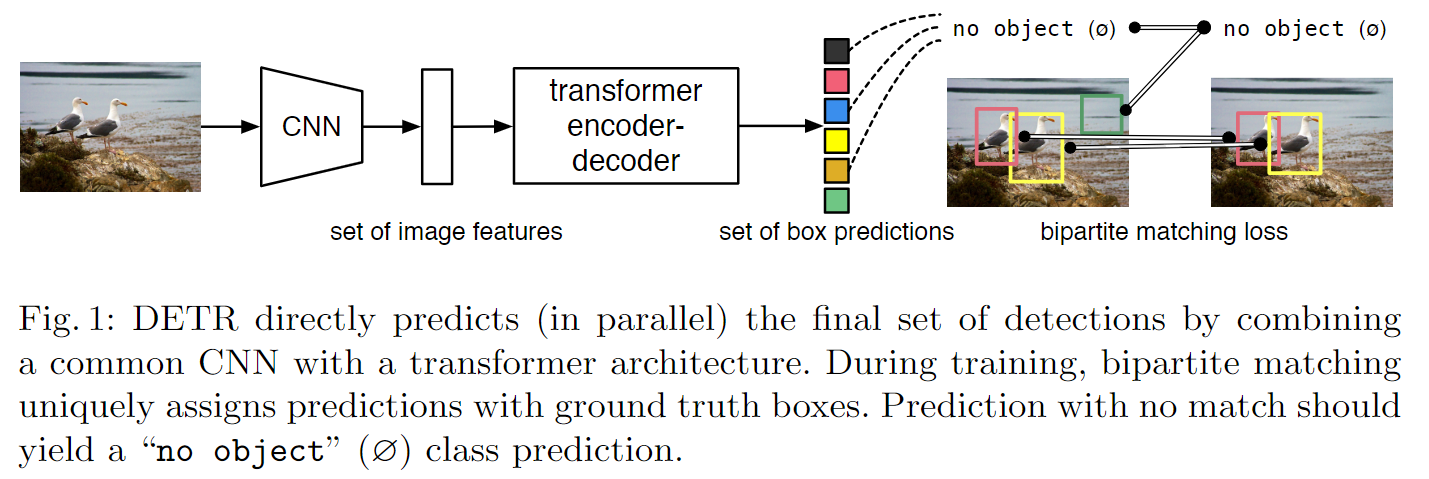
训练过程如下:
-
CNN:抽取特征 -
Transformer encoder:每个特征会和图中其他所有特征交互,这样网络大概知道哪块是哪个物体,对同一个物体只出一个框,所以这种全局建模的方式有利于移除冗余的框。 -
Decoder:生成预测框 -
预测框和GT框做匹配:将这个过程看成集合预测的问题,在匹配上的框上作loss。
推理过程中置信度大于0.7的物体才会被保留
Model
Set prediction loss
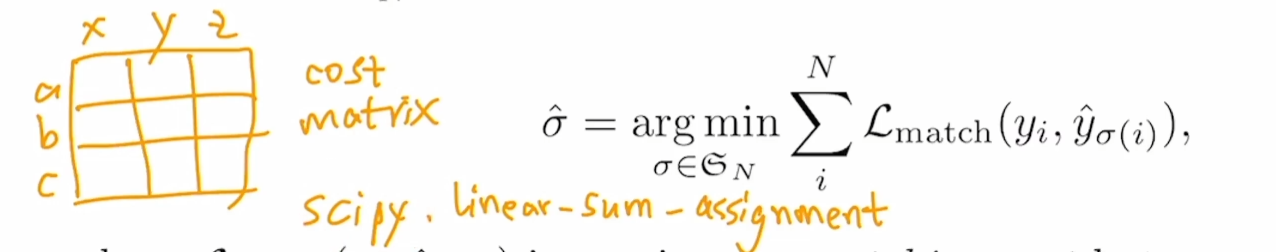

二分图匹配的例子:如何分配一些工人做一些工作使最后支出最小? 最优二分图匹配即最后有唯一解达成目标且成本最低。遍历算法来解决复杂度太高,常用匈牙利算法即Scipy包中的linear-sum-assignment函数来完成,该函数的输入就是Cost matrix, 输出即最优排列。可以将100个预测框视为a、b、c,GT框视为x、y、z ,检测中Cost matrix是损失值。最终输出的是与GT唯一匹配的预测框。
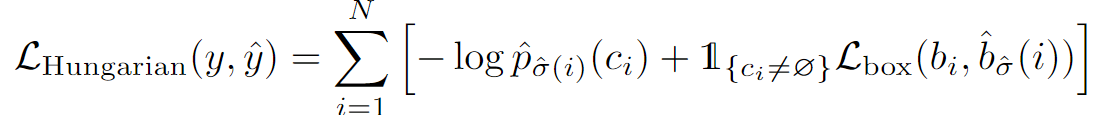


完成了这个最优匹配操作,就可以计算一个真正的目标函数loss,从而更新模型参数。
DETR architecture
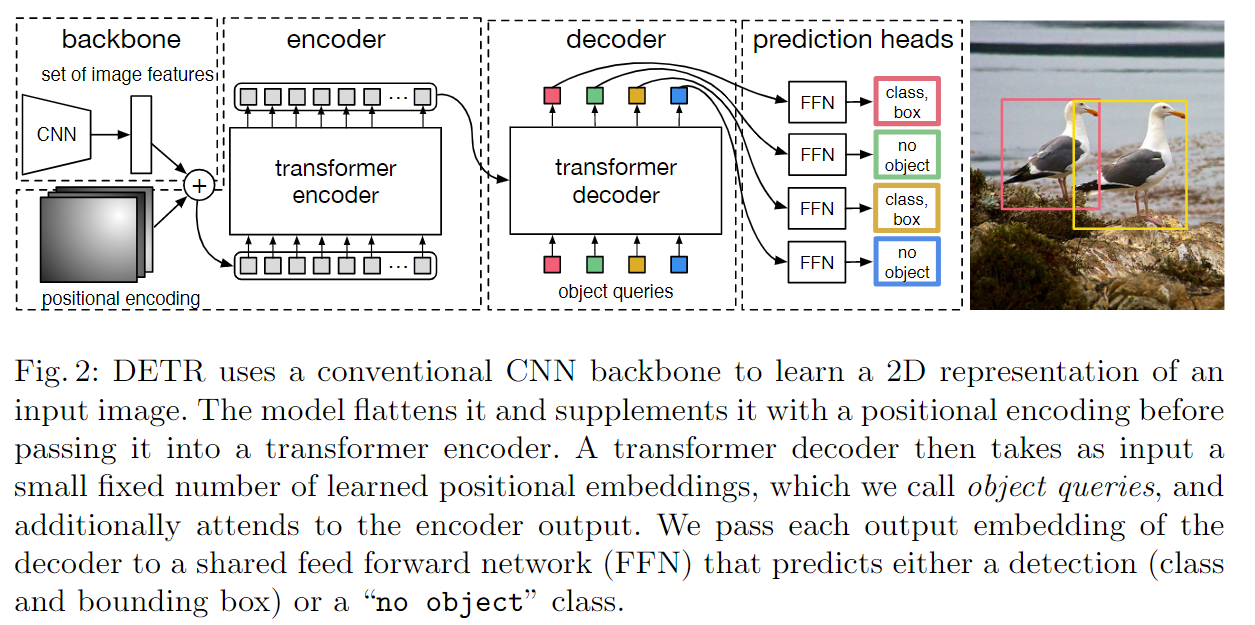
Visualizing

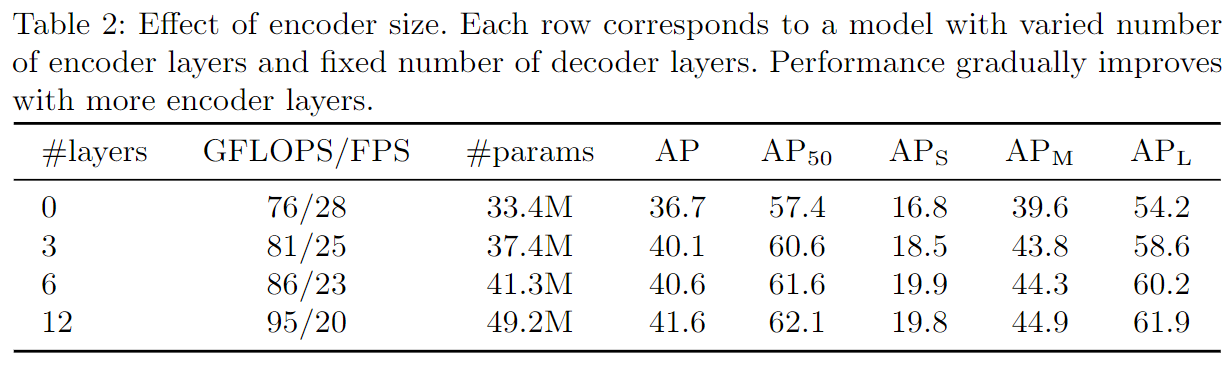
Encoder越深不同物体的区分性越好

可视化结果: 仅使用Transformer Encoder图像中的物体已经有很好的区分了,再此基础上做Decoder后效果更佳。编解码一个都不能少,Encoder在学习一个全局的特征,将物体与物体区分开;Decoder在前面的基础上只需对头、尾巴等对象边界特征进行学习以解决遮挡问题来更好的区分物体

上图为object query的可视化,每个正方形代表一个object query,替代了anchor的生成机制,不同在于它是自己学的。以第一个为例,该object query学到最后,会问每个输入图片在左下角有没有看到小物体,在中间有没有看到横向的大物体,有的话告诉我。这100个object query相当于100个不停问问题的人,得到的答案就是目标框。
1 | import torch |